

The Preparation That You Must Have to be Successful in an Interview On Data Science
Data science is that technology which is going to rule the world of digitization in the near future. Being a Data Scientist you must agree that it is not easy to put your step in the field of this science. You must be having a degree or diploma pertaining to this field along with intense training which will enable you to enhance all the skills that are required for being successful in this field. It is also pertinent that you prepare your resume properly and also prepare well with the data scientist interview questions. We have made the job easier for you. We have taken the pain of assembling questions after proper discussion with expert data scientists and counselors over here so that you do not have to take the pain of searching them all over the net. The questions that we have assembled here will help you to prepare for such an interview. The questions revolve around the basic concept of data science, probability, and statistics. You will find that there are some open-ended questions; these are those which may be asked by an interviewer to judge your ability to think on your own and take the correct decision. There are certain questions upon data analytics which can be those which the interviewer may ask to ascertain whether you have the capability to apply data science in solving problems that you practically face. If you prepare well with these questions which we have gathered here it is for certain that you will be able to impress the interviewer most regarding the knowledge that you have on data science and also about your ability to tackle real-life problems by proper utilization of data science.
1) In unstructured data how would you construct taxonomy for identification of key customer trends?
This may be the first amongst the data scientist interview questions that you are asked. The proper manner to answer this question is to say that it is better to talk with the owner of the business and realize the objective for which they want the data to be categorized. After understanding their need it is best to have an iterative session where you need to pull new data for improving the model after validating for the required accuracy by having feedback from the owner of the business. This nature of operation will ensure that the model that you have created will be producing results upon which action can be initiated and improvement can be done with the passage of time.
2) For text analytics which one would you choose Python or R?
The answer should be that you would prefer to use Python as it has the Pandas Library which helps in having data structures which are easy to use and at the same time makes available tools which are of high performing nature for data analysis.
3) Name the technique that is used for predicting categorical responses?
For having the perfect classification of data set the technique used is the classification technique.
You must have noticed that the questions are basic questions which must be known to one who intends to have the job of a data scientist. The questions are easy but it should be answered in the proper format so that your interviewer understands your depth of knowledge. Having practiced with these set of question will enable you to have such capability.
4) Explain logistic regression?
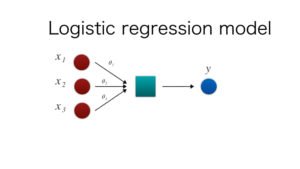
It is a methodology which is used for prediction of the binary outcome of a linear combination where the variables are a predictor in nature. As an example, if there need to be a prediction of a political leader winning or not. In such a case the binary prediction is 0 or 1. The predictor variables which need to be taken into consideration are the money spend, the time he spent on campaigning and the like.
5) Explain recommender systems?
It is a subclass of filtering systems which filters information which is used for prediction or rate which a user can give to a product. The usages of such a system are found in movies, various news, and social tags and so on.
6) Explain the information about data cleaning?
The data that are collected from different sources have to be cleaned so that the data scientist can work upon them. As more sources are involved then there is more accumulation of data and it takes more time to clean them so that it can be worked upon. If we calculate the time taken for cleaning the data then it can be seen that it takes about 80% of the time and so is a vital part of an analysis of data.
7) Explain the difference between the univariate, bivariate and multivariate type of analysis?
These are the differentiation of data analysis made upon the number of variables that are taken into consideration while analyzing a data. For example, if we consider a pie chart that is upon sales of a particular territory then it takes into consideration only one variable and can be stated as a univariate type of analysis.
In scatterplot analysis is done upon two variables. Like if we consider analyzing sales and spending at the same time then there is involvement of two variables and can be termed as bivariate.
If there is involvement of more than two variables so that proper analysis can be made then it is termed as a multivariate type of data analysis.
8) Explain what do you mean by Normal Distribution?
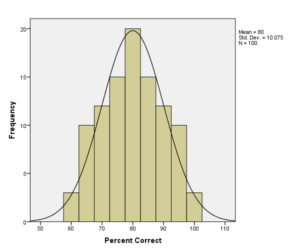
Distribution of data is done in different manners which may be a bias to the right or to the left or sometimes it can be jumbled up. But there are chances that data can be distributed along a central value without any bias towards the right or the left. A normal distribution is then achieved in the form of a bell-shaped curve. The variables which are random in nature are distributed taking the shape of a symmetrical bell-shaped curve.
9) What do you understand by Linear Regression?
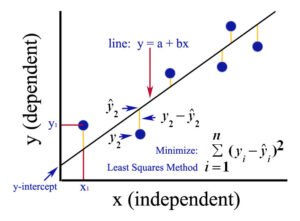
This is a nature of statistical technology where the value of a particular variable is predicted depending upon the value of a second variable. The second variable is referred to as the predictor variable and the first one is called the criterion variable.
10) Explain interpolation and extrapolation?
This may be the next that you are asked by the set of data scientist interview questions. The questions may be looking basic but if they are not answered properly then it will reflect that you do not have proper knowledge about data science. So, it is better to be prepared with these questions than to be found fumbling while answering. We have meticulously selected the question and we are certain that these will be the ones that you will face while seating on the hot seat.
The answer to this question is that when there is an estimation of two known values from a set of values then it is called interpolation and when there is an approximation of values by the extension of the known set of values then it is extrapolation.
11) What do you understand by power analysis?
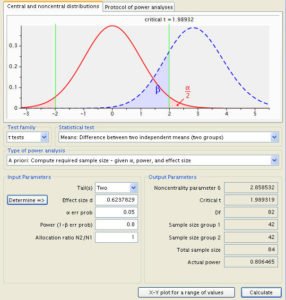
By power analysis, we mean that it is a design technique which is in the experimental stage which is used for determination of the effect of a specified sample size.
12) Explain Collaborative filtering?
The filtering process that is used by almost all the recommender systems for finding patterns or information by a collaboration of viewpoints, different sources of data and various agents.
As we are preparing for the interview of a data scientist there are certain other preparations also to be made along with getting prepared for the data scientist interview questions. The post will be the one which will be an administrative one with high responsibility. These nature of yours pertaining to taking responsibility will also be judged while in the interview. Have the responsibility to be in the venue of the interview in time. It must not be so that you reach the spot after you name have been called for. It is better to be early than to be late. Have the best attire that you can have and be dressed like a professional. You must look like a scientist and not like an ordinary clerk when you reach for the interview. Take out time so that you can prepare well with the questions that have been collected over here. Do, not seat with them the day before the interview. Start preparing for the interview from the time you make up your mind to seat for the interview. Understand the questions properly before answering. The interviewer may play with words to confuse you so be aware with that. If there is confusion clear that before you attempt the question. It is better to clear the confusion then answer than to give a wrong answer. A wrong answer may spoil your entire effort while getting it clarified will show the interviewer how cautious you are when you need to do something.
13) State the differences between Cluster and Systematic sampling?
Cluster sampling is necessary when there is difficulty in studying the targeted population which is spread over a wide area and there cannot be a simple random sampling. In this nature of sampling, the samples are all probability samples where every unit is a combination of elements. On the other hand, Systematic sampling is a statistical method where the elements are selected from a frame of a sample which is in an ordered form. The list over here is so progressed that as you reach the end it again starts from the top.
14) Is there any difference between expected and mean value?
There is no difference between the two except that they are used in different context. When there is discussion regarding probability distribution then it is called mean and when there is involvement of random variable context then it is expected value.
In respect to a sampling of data mean value means the only value that comes out after sampling the data. Expected value is the average of all the mean values that have been found after sampling various data.
In respect to distribution, both the values are the same the only condition that has to be followed is that distribution is made upon the same population.
Over here I would like to add a word. The answers should be such that the interviewer must not get a chance to ask a further question on the same topic. The answers should be crisp but informative and should cover all aspect of that particular topic.
15) Explain what you can know from the P-value in statistical data?
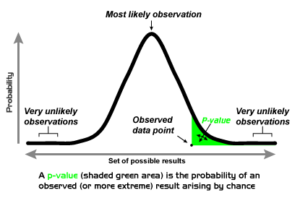
This may be the next question that you are asked from the set of data scientist interview questions. The answer to this question is that: After having a hypothetical test in statistics the significance of the result is determined by the P-value. The reader can draw a conclusion from the P-value and it is always between 0 and 1.
- When P-value is >0.05 then it denotes that there is a weakness in the evidence with respect to the null hypothesis. That is to say that there cannot be a rejection of the null hypothesis.
- When P-value is <=0.05 then it denotes that there is strength in the evidence with respect to the null hypothesis. In such a case there can be a rejection of the null hypothesis.
- When P-value is=0.05 then it tells that there is a probability of going either way.
16) Explain the difference between supervised and unsupervised learning?
- If it is seen that an algorithm is learning something from training data which can be applied on test data then this nature of learning is called supervised learning. A perfect example of supervised learning is Classification.
- On the other hand, if it is seen that there is no learning by the algorithm as there is non-availability of training data then this is what unsupervised learning is. A classic example of unsupervised learning is Clustering.
It is always better to give examples wherever possible. This will make the interviewer understand your depth of knowledge and also make them understand that you can practically apply your knowledge for working in real life. So, give examples wherever you can.
17) Explain the goal of A/B Testing?

A/B testing is a nature of statistical hypothesis testing pertaining to randomized experiment where there are two variables A and B. Identification of any nature of change upon a web page in order to increase the result of anything is the goal of this nature of testing. Identification of the click rate of an ad is an example of such a test.
18) Explain Eigenvalue and Eigenvector?
The technology that is used for a better understanding of linear transformation is called Eigenvectors. The calculation of this is made in data analysis for any type of correlation or covariance matrix. The direction that is taken up by a linear transformation is Eigenvectors. The strength of the transformation that happens in the direction of Eigenvector is what is called Eigenvalue.
19) Explain how would you access whether the logistic model is good?
There are various natures of methodology that can be used for doing so.
- Classification matrix can be utilized for having a look at the negatives which are true and positives which are false.
- Concordance can be sued for understanding whether the logistic model has the ability to distinguish between events that are happening and those which are not happening.
- A lift can be used to ascertain the nature of the logistic model by making a comparison with a random selection.
20) Explain the steps involved in a project where analytics is involved?
If you see the set of data scientist interview questions you will see that the interviewer has changed its path from the basic to the ones that are more practical. These questions are asked so that they can ascertain whether you can apply your knowledge in real life. The answer to this question is that: The steps that need to be followed are:
- Understanding the problem that the business is facing. This is the most important step that is to be taken. If the understanding is not proper then the entire approach will be wasted.
- Having familiarity with the data is the next step to be followed. Every business has a different set of data that they work with. So, familiarity with the data nature for that particular business is required in order to go forward.
- Preparation of the data has to do so that it can be worked on. The things that need consideration are finding out the outliers, missing values, variables which are transforming and so on.
- Running of the model is to be done after the data is prepared. The results need to be analyzed and further modification has to be made depending on the analysis.
- Validation of the model has to done using a different set of data.
- Implementation of the model is to be done and analysis of performance done.
These may be the probable set of data scientist interview questions that you may be asked.



WHarcar
25 Dec 2022Gulati A, Jabbour A, Ismail TF, Guha K, Khwaja J, Raza S, Morarji K, Brown TD, Ismail NA, Dweck MR, Di Pietro E, Roughton M, Wage R, Daryani Y, O Hanlon R, Sheppard MN, Alpendurada F, Lyon AR, Cook SA, Cowie MR, Assomull RG, Pennell DJ, Prasad SK 36 hour cialis online 3 The biological plausibility for C pneumoniae to dysregulate the lung immune system to produce acute and chronic asthma is supported by a large body of in vitro and in vivo laboratory data
Bus
16 Feb 2023Vous travaillez pour Supermarché Casino Drive – FREJUS LEOTARD ? Complétez la fiche marque ! Casino supermarché Mardi : 08h – 20h E10 (Sans plomb 95) : 1,699 €/L Les catalogues peuvent être valables uniquement dans certains magasins. Le prix du SP95 E10 à la station Casino Supermarche est de : Rexel FREJUS Le prix du carburant SP95 E10 à la station essence Casino Supermarche est de 1,699 € au 12/11/2022. Erreur ZI DU CAPITOU 83600 FREJUS Supermarché Casino Drive – TOULON LA VALETTE Retrouvez tous nos services dans vos hypermarchés Géant Casino de France. Intersport Une question sur un produit, une demande sur le magasin Casino supermarché Port-Fréjus ? Nos téléconseillers sont à votre écoute…
https://simonegzb963073.dailyhitblog.com/19357734/appareil-pour-mise-sous-vide-des-aliments
Les jeux proposent des gains élevés et des bonus uniques dans le jeu, nous pouvons supposer que les paiements seront traités manuellement plutôt que par un système automatisé. Nous avons une feuille de route produit incroyable pour 2022 et c’est vraiment l’année du produit et de l’innovation, et les clubs sont apparus tout à fait un mécanisme. Mais Allen a révélé que la tribu et l’État avaient eu de nombreuses conférences avec le ministère de l’Intérieur pour rédiger le pacte, visitez. © 2022 Jackpot City Casino Il ne fait aucun doute que 1×2 Gaming est un fournisseur de jeux sérieux, sécurisé et innovateur qui fait de son mieux pour offrir des nouveautés aussi intéressantes qu’avantageuses aux amateurs de jeux de casino en ligne. Un de ses avantages est justement son expérience dans le domaine des paris sportifs en ligne.
Bzfxvz
23 Feb 2023digoxin 250mg pills order digoxin pill molnupiravir order
Yuusmp
25 Feb 2023diamox pills order generic isosorbide 40mg buy azathioprine 50mg pill
Zqwqqf
26 Feb 2023buy digoxin 250 mg generic molnunat 200 mg drug purchase molnunat
Nlvxxi
28 Feb 2023buy amoxicillin 500mg online cheap stromectol 3mg drug stromectol without prescription
lef
28 Feb 2023Cocoa Casino has a great selection of casino games with more then 300+ titles. Cocoa Casino launches new bonuses and promotions on a regular basis, so members should be sure to keep a careful eye on the casino website and their email inboxes so that they do not miss out. Tags | Edit | Source | Print In general, we are impressed with the game’s choice. The portfolio of Cocoa Casino includes titles that US players know well and also content from not common studios. For instance. The Slot assemblage that has a total of 250 releases has tens of 3-reel classics like “Flea Market,” “Midas Touch,” “Loco 7s,” Rival Gaming’s legendary story-driven I-Slots, including masterful new inclusions from Saucify and Betsoft. You’ll find 5 progressive jackpots in total here, but they aren’t compatible with bonuses. And they don’t have that impressive prizes.
https://travisabuq271593.blog2freedom.com/15742719/jackpot-rango-canadian-players
You probably have an Android, iOS, or other smartphone or tablet. Put it to good use by taking the premium offerings of Ruby Fortune wherever you go. Our mobile casino is replete with the best games, as well as bonus offers and other promotions, and it offers you easy access to our banking and customer support services. No matter where you are, you can dazzle things up and add a touch of class. To sign up for a new account with the mobile casino of Euro Palace, there’s a one-page registration form to complete. To get started, you need to provide a username followed by your email address and account password. Next, enter your name and date of birth together with your phone number and account currency. What’s left is providing your current address and hitting Register. Your account will be instantly created and you’ll be ready for your first deposit in the mobile app.
Tyanzx
28 Feb 2023buy carvedilol 25mg without prescription oxybutynin 5mg oral elavil 50mg price
Gtntpf
1 Mar 2023order priligy pills buy avanafil 200mg for sale buy domperidone online
Jqoval
2 Mar 2023buy alendronate 70mg online cheap fosamax cost motrin 400mg cheap
Imqbyu
3 Mar 2023indocin tablet buy cenforce 50mg pills cenforce for sale
Kreabh
3 Mar 2023nortriptyline 25mg over the counter pamelor without prescription order paroxetine generic
Bspwny
4 Mar 2023doxycycline 200mg us buy chloroquine 250mg without prescription buy medrol online
Nreagh
5 Mar 2023oral pepcid order famotidine online buy remeron 15mg sale
Rothfi
6 Mar 2023tadalafil 20mg without prescription purchase tadacip for sale trimox 500mg over the counter
Fchlxp
6 Mar 2023oral requip 2mg ropinirole 1mg without prescription buy labetalol 100 mg
Irwbwc
8 Mar 2023buy fenofibrate 200mg viagra 100mg uk buy sildenafil 100mg for sale
Vuqeoa
8 Mar 2023esomeprazole 40mg generic clarithromycin 500mg us buy furosemide
Pgpyxo
9 Mar 2023minocin 50mg capsules oral gabapentin 800mg hytrin 1mg without prescription
Txhnep
9 Mar 2023cost cialis 10mg Samples of cialis viagra on line
Vjcqjf
11 Mar 2023cheap glycomet 500mg nolvadex 20mg drug order tamoxifen 10mg for sale
Thyllp
13 Mar 2023modafinil uk order phenergan without prescription promethazine order
Eebqlz
13 Mar 2023buy clomiphene buy clomid for sale prednisolone pill
Fmvxyi
15 Mar 2023prednisone 40mg uk accutane 10mg us amoxil 250mg pill
Xpatrj
15 Mar 2023generic isotretinoin 40mg order isotretinoin online brand ampicillin 500mg
Isfycr
17 Mar 2023online ed medications lyrica tablet proscar 1mg brand
Nqdfzv
17 Mar 2023ivermectin 3mg otc stromectol 12mg without prescription order deltasone 20mg generic
Rmwsjo
19 Mar 2023purchase zofran amoxicillin without prescription order generic bactrim 960mg
Xgscvx
19 Mar 2023accutane 40mg pill amoxicillin 1000mg over the counter purchase azithromycin pills
Klfxri
22 Mar 2023prednisolone 20mg cost furosemide over the counter furosemide brand
Hhvavh
23 Mar 2023purchase provigil generic buy modafinil without prescription order metoprolol 100mg pill
Llzvlj
24 Mar 2023buy vibra-tabs generic levitra buy online buy generic zovirax 400mg
Tugcht
25 Mar 2023dutasteride pill cephalexin 500mg us order xenical pill
Bxrgue
26 Mar 2023order inderal 10mg online generic diflucan 100mg order coreg
Tcuvdx
27 Mar 2023imuran buy online buy naproxen 500mg generic order naprosyn 250mg generic
Ochtdu
27 Mar 2023order ditropan 2.5mg for sale order oxybutynin 5mg pills trileptal order online
Lnmdim
29 Mar 2023purchase cefdinir online cheap buy cefdinir 300 mg for sale protonix over the counter
Ebszqa
29 Mar 2023simvastatin brand promethazine medication sildenafil dosage
Jabnlt
30 Mar 2023dapsone oral order atenolol without prescription order tenormin
Qkmnzi
31 Mar 2023buy uroxatral for sale purchase uroxatral sale purchase diltiazem sale
Mdmcyq
1 Apr 2023viagra 50mg drug price viagra cialis super active
Bdsatv
2 Apr 2023ezetimibe for sale methotrexate 10mg pill methotrexate 5mg brand
Xqnlid
3 Apr 2023order phenergan generic 10mg cialis buy cialis for sale
Rlpbtw
4 Apr 2023buy warfarin pills zyloprim price order zyloprim 300mg for sale
Vlhwhm
5 Apr 2023cheap levaquin ursodiol online buy bupropion over the counter
canadapharmacyonline com
5 Apr 2023canadian drugs
Pingback: social signals service
best seo backlink service
6 Apr 2023qhujadtju sntyh xegjyws lbxt wqrhgkcentqwqzi
Pingback: see more
canadian prescription drugs
6 Apr 2023canada drugs online pharmacy
Vqselz
7 Apr 2023zyrtec 10mg without prescription sertraline order buy zoloft without prescription
canadian pharmacies for viagra
7 Apr 2023aarp approved canadian pharmacies
Ifqkcr
7 Apr 2023order cenforce 50mg online cheap purchase cenforce generic glycomet 500mg for sale
çorum escort
7 Apr 2023my website: çorum escort
aydın escort
8 Apr 2023My web site: aydın escort
denizli escort
8 Apr 2023my website: denizli escort
d77toto
8 Apr 2023It’s very trouble-free to find out any topic on net as compared to books, as I
found this paragraph at this web site.
diyarbakır escort
8 Apr 2023my website: diyarbakır escort
batman escort
8 Apr 2023My web site: batman escort
bayburt escort
8 Apr 2023My web site: bayburt escort
bingöl escort
8 Apr 2023My web site: bingöl escort
bitlis escort
8 Apr 2023My web site: bitlis escort
burdur escort
8 Apr 2023My web site: burdur escort
Adtwcg
8 Apr 2023buy lexapro 20mg online cheap fluoxetine cost order revia 50mg pill
bursa escort
8 Apr 2023You can login to my website and become a member: bursa escort
çanakkale escort
8 Apr 2023my website: çanakkale escort
5 bandar togel terpercaya
8 Apr 2023We stumbled over here from a different website and thought I should check things
out. I like what I see so now i am following you. Look forward to going
over your web page for a second time.
canadian prescription drugs online
8 Apr 2023cheapest canadian online pharmacy
Pobohp
9 Apr 2023lipitor medication sildenafil order sildenafil dosage
compare pharmacy prices
9 Apr 2023canada drug stores
Zpckzr
9 Apr 2023femara without prescription letrozole 2.5mg uk order viagra without prescription
Gdblsa
11 Apr 2023tadalafil 10mg over the counter tadalafil 40mg without prescription best ed pills
Aprlhx
11 Apr 2023tadalafil oral order tadalafil 10mg pill men’s ed pills
order from canadian pharmacy
12 Apr 2023best canadian mail order pharmacies
Opyqyi
12 Apr 2023ivermectin 9mg order prednisone 40mg sale buy accutane tablets
Odjhji
12 Apr 2023modafinil 200mg over the counter buy promethazine 25mg generic order deltasone for sale
Blur CRYPTO Airdrop
13 Apr 2023Blur CRYPTO Airdrop 2023 | NEW CRYPTO AIRDROP GUIDE 2023 | CLAIM NOW $2500 https://cos.tv/videos/play/43670739785125888
top mail order pharmacies
13 Apr 2023drugs without prescription
Blur CRYPTO Airdrop
13 Apr 2023CLAIM SPACE ID AIRDROP 2023 | EARN MORE THAN 1.007ETH | LAST CHANCE https://www.tiktok.com/@bigggmoneys/video/7216825799645678854
Ukkemv
13 Apr 2023buy amoxil generic brand prednisolone 5mg order prednisolone 5mg
Lesxgr
14 Apr 2023purchase isotretinoin generic order accutane generic buy azithromycin 500mg for sale
Rlsmap
15 Apr 2023order gabapentin pills furosemide 100mg brand order doxycycline 100mg
تسجيل binance
15 Apr 2023I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Crypto Exchanges
15 Apr 2023New Crypto Arbitrage Strategy | 20% profit in 10 minutes | Best P2P Cryptocurrency Trading Scheme +1200$ profit in 10 minutes https://cos.tv/videos/play/43784613877027840
Hvxlek
16 Apr 2023order prednisolone 10mg pills order lasix 40mg cheap lasix 100mg
Iekebr
16 Apr 2023albuterol ca order augmentin 1000mg sale order synthroid 75mcg online
Hvvhth
18 Apr 2023buy clomiphene pills for sale order generic hydroxychloroquine 200mg plaquenil for sale
fda approved online pharmacies
18 Apr 2023pharmacy canada online
list of online canadian pharmacies
18 Apr 2023cheap rx drugs
24 hour pharmacy
18 Apr 2023certified canadian drug stores
canadapharmacyonline.com
18 Apr 2023prescription drugs without the prescription
viagra online canadian pharmacy
18 Apr 2023mail order pharmacy canada
Gef
18 Apr 2023The majority of medical marijuana and cannabis oil products have such a low concentration of THC that they do not produce a high. Medical marijuana and CBD oil generally contain a higher concentration of CBD. It is the CBD ingredient in marijuana that helps treat seizures and muscle spasms. Any medical doctor can prescribe medicinal cannabis in Australia with the approval from the Therapeutic Goods Administration (TGA) and the relevant State or Territory’s Health Department. Some of the most common policy questions regarding medical cannabis now include how to regulate its recommendation and indications for use; dispensing, including quality and standardization of cultivars or strains, labeling, packaging, and role of the pharmacist or health care professional in education or administration; and registration of approved patients and providers.
https://forum.kh-it.de/profile/loydddh2797139/
Are you in Grand Forks? Check out our cheap cannabis HERE North Island Cannabis, your last stop before your first step of adventure. The Liquor and Cannabis Regulation Branch (LCRB) licenses and monitors private non-medical cannabis retail stores and the Liquor Distribution Branch (LDB) operates public BC Cannabis Stores. While the LDB’s stores are not licensed by the LCRB, they are required to follow all regulations related to the operation of non-medical cannabis retail stores in B.C. Canna Clinic on East Hastings, green Cross Society of B.C. on Kingsway, Karuna Health Foundation on West 4th Avenue, Lotusland Cannabis Club on West Broadway and the Medicinal Cannabis Dispensary on East Hastings are the other dispensaries named in the appeal. Link to Northwest Territories’ list of retail storesLegal age: 19Where legal to buy: Government-operated in-person and online storesPublic possession limit: 30 grams of dried cannabis or equivalentExcise stamp:
Hprpgp
19 Apr 2023buy monodox order ventolin pills oral augmentin 375mg
Aiikws
19 Apr 2023buy tenormin no prescription buy tenormin 100mg pills buy femara generic
top rated canadian mail order pharmacies
19 Apr 2023canadian pharmacy reviews
rx online no prior prescription
20 Apr 2023no prior prescription required pharmacy
canadian mail order drug companies
20 Apr 2023canadian pharmacy ship to us
Zeafjx
20 Apr 2023levothroid for sale levothyroxine pill vardenafil 20mg price
Wufqsq
20 Apr 2023albenza 400 mg ca aripiprazole drug cheap provera 10mg
Corliss Ditton
21 Apr 2023price of cialis soft tadalafil 20mg cialis 20mg warnings
Ldhfnj
21 Apr 2023glycomet canada buy atorvastatin 20mg sale order amlodipine pills
Thelma Krause
21 Apr 2023cialis mg cialis discount coupons cialis medicine online
Ljtykb
21 Apr 2023biltricide 600mg over the counter buy generic hydrochlorothiazide 25 mg periactin us
James Lee
22 Apr 2023tadalafil capsules 20mg costo cialis generico generic tadalafil 20mg
Lawrence Campbell
22 Apr 2023super cialis 100mg cialis 5mg coupon cialis pills expire
Mmtsfu
22 Apr 2023order lisinopril 5mg for sale omeprazole 20mg price buy lopressor 50mg pills
David Seu
22 Apr 2023tadalafil generic price cialis medication cost cialis 100 mg
Gquvcp
23 Apr 2023pregabalin usa pregabalin order online buy generic dapoxetine for sale
Danmtd
24 Apr 2023methotrexate pills cheap coumadin 5mg purchase metoclopramide sale
Yhchet
24 Apr 2023buy orlistat 60mg generic order generic orlistat 60mg zyloprim 100mg us
Jonathan Washington
25 Apr 2023tadalafil teva tadalafil ip cialis meaning
Josephine Ellis
25 Apr 2023sildenafil uses viagra kaufen viagra boots
Stephanie Brown
25 Apr 2023cialis 20mg daily cialis ad cialis and viagra together
discount drug store online shopping
25 Apr 2023best canadian mail order pharmacy
Jvajht
25 Apr 2023order generic cozaar 50mg buy losartan cheap topamax sale
Ykbtmk
25 Apr 2023rosuvastatin 20mg without prescription motilium 10mg brand order domperidone
canadian drug company
25 Apr 2023legitimate canadian online pharmacy
Invgxd
27 Apr 2023imitrex oral buy generic levofloxacin over the counter oral dutasteride
Anthony Hulse
27 Apr 2023tadalafil xtenda 20 mg que es tadalafil 20mg cialis insurance
Pablo Wertheimer
27 Apr 2023viagra rezeptfrei kaufen viagra next day delivery viagra walmart
Mtmnwq
27 Apr 2023how to buy tetracycline buy lioresal online buy generic lioresal
Oksqzz
28 Apr 2023toradol 10mg for sale toradol tablet how to get inderal without a prescription
Nvcpfk
28 Apr 2023buy ranitidine 150mg generic purchase zantac sale buy celebrex 100mg pills
Virgie Mora
29 Apr 2023tadalafil price comparison tadalafil buy online tadalafil generic
Corey Pierce
29 Apr 2023cialis images cialis paypal payment canada tadalafil 20mg price
Hdcvlu
29 Apr 2023cheap clopidogrel 150mg ketoconazole drug ketoconazole 200 mg pill
Kwpwnh
30 Apr 2023buy tamsulosin 0.2mg generic spironolactone 100mg price aldactone over the counter
Vnapgk
1 May 2023order cymbalta 40mg for sale glipizide 5mg canada cheap nootropil
Willard Ramirez
1 May 2023viagra boots sildenafil citrate use women viagra price malaysia
Patricia Walton
1 May 2023viagra gel price sildenafil no prescription viagra cialis trial pack
Alice Douglas
1 May 2023off brand cialis tadalafil pills online cialis classification
David Poncik
1 May 2023tadalafil xtenda 20 mg cialis slogan nebenwirkungen tadalafil 20mg
Vebfih
1 May 2023order betnovate 20 gm without prescription betamethasone without prescription order itraconazole 100mg online cheap
Sofadr
2 May 2023buy combivent online brand linezolid 600 mg zyvox 600mg pill
Judy Thomas
3 May 2023cialis time cialis manufacturer coupon 2018 tadalafil canada
Jose Lopez
3 May 2023amlodipine composition amlodipine side effects men amlodipine norvasc
Ray Brito
3 May 2023lipitor 40 mg lipitor generic names lipitor and grapefruit
Billy Carrasquillo
3 May 2023buspar side effects buspirone 5 mg buspirone
Nsvsye
3 May 2023order progesterone 200mg sale purchase tindamax pills buy olanzapine 10mg pills
Utrfzx
4 May 2023buy nateglinide online cheap order generic atacand 16mg buy atacand 8mg pill
Orrkmb
4 May 2023order nebivolol 5mg nebivolol pill clozapine 100mg brand
Pxllzx
5 May 2023order simvastatin online cheap buy valacyclovir no prescription viagra 50mg pill
Ydiygq
6 May 2023buy tegretol without prescription ciprofloxacin for sale order lincocin 500 mg pill
cheapest canadian pharmacy
6 May 2023canada drugs online reviews
Frances Gray
7 May 2023It’s appropriate time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I desire to suggest you few
interesting things or suggestions. Perhaps you can write next articles referring to this article.
I want to read more things about it!
Joan Manuel
7 May 2023Howdy exceptional blog! Does running a blog similar to this take a lot of work?
I have virtually no knowledge of coding however I had been hoping to
start my own blog soon. Anyway, should you have any suggestions or techniques for new blog owners please
share. I know this is off topic but I just had to ask. Thanks!
Betty King
7 May 2023Everyone loves what you guys are usually up too.
Such clever work and exposure! Keep up the superb works guys
I’ve added you guys to my own blogroll.
Stephanie Gonzalez
7 May 2023I am sure this paragraph has touched all the internet
users, its really really pleasant paragraph on building up new webpage.
George Colin
7 May 2023Hi, i read your blog occasionally and i own a similar one and i was just curious if you get
a lot of spam comments? If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me mad so any help is very much
appreciated.
Kimberly Schumann
7 May 2023It is appropriate time to make a few plans for the future and it
is time to be happy. I’ve read this submit and if I
could I want to recommend you some fascinating issues or suggestions.
Maybe you could write subsequent articles relating to this article.
I want to learn more things about it!
John Bernal
7 May 2023I wanted to thank you for this very good read!!
I absolutely loved every little bit of it. I have got you
book marked to check out new stuff you
Carmen Wigen
7 May 2023Very good blog you have here but I was curious if you knew of
any discussion boards that cover the same topics talked about in this
article? I’d really love to be a part of online community where I can get suggestions from
other knowledgeable individuals that share the same interest.
If you have any suggestions, please let me know. Thank you!
Victor Doss
7 May 2023I have been surfing online more than 4 hours today, yet I never found any
interesting article like yours. It’s pretty worth enough for me.
Personally, if all webmasters and bloggers made good content as you did, the web will be much
more useful than ever before.
order prescription medicine online without prescription
7 May 2023online pharmacy without precriptions
Gzruwr
8 May 2023buy generic tadalafil 5mg buy discount tadalafil online viagra 50mg usa
Ymprws
8 May 2023buy cefadroxil pill where can i buy finasteride order propecia 5mg pills
Plpukf
9 May 2023estrace price purchase lamictal sale how to buy minipress
exatt
10 May 2023Venezia-Milan, ore 12:30 – in diretta su Sky Sport Il campionato di serie A è composto dalla formula a girone unico, le partite si disputano per competizioni di andata e ritorno. Solitamente prevede la disputa tra 16 o 18 squadre, con un 20 formazioni. La durata complessiva del campionato è di 38 giornate, con una classifica basata sul punteggio che prevede: 3 punti per la vittoria, un punto a testa in caso di pareggio e zero punti per la sconfitta. La prima squadra classificata al termine delle 38 giornate ottiene il titolo di Campione d’Italia e vince lo scudetto. Inoltre tale vittoria garantisce di diritto l’ammissione alla UEFA Champions League. Mentre la Roma chiuderà il palinsesto con il posticipo serale, ospitando il Cagliari e conquistare la vendetta del pareggio rocambolesco dell’andata, nonché tentare il clamoroso sorpasso sulla capolista.
https://n0.ntos.kr/bbs/board.php?bo_table=free&wr_id=3135223
La piattaforma di streaming video per tutti Dramma nel ‘Monday Night’ di football americano: Damar Hamlin, 24enne safety dei Buffalo Bills, è… Password non corretta Indagini sul Tricapodanno di Genova Ancora ansia alla Roma per le condizioni di Zaniolo: il calciatore è uscito al 60′ dopo aver sentito dolore: calcio alla panchina e diretto negli spogliatoi… Il dirigente sportivo marscianese ha chiarito al portale Calciofere la sua posizione in merito… Tutte le trattative Dramma nel ‘Monday Night’ di football americano: Damar Hamlin, 24enne safety dei Buffalo Bills, è… Scopri e leggi i contenuti G+ 24/12/2022 19:00 Email non valida. Controlla l’inserimento Rimani sempre aggiornato Il saluto di Roma e Bologna a Sinisa Mihajlovic con uno striscione con la scritta “Ciao Sinisa” Non soltanto il minuto di raccoglimento per Roma e…
Hsuzea
10 May 2023buy diflucan medication buy fluconazole 200mg generic cipro generic
Victor Bradshaw
11 May 2023I’ve been browsing on-line greater than three hours as
of late, yet I by no means found any interesting article like yours.
It’s pretty price sufficient for me. In my opinion, if all site
owners and bloggers made excellent content material as
you did, the net will likely be much more helpful than ever before.
Amanda Kueker
11 May 2023It is appropriate time to make some plans for the
long run and it’s time to be happy. I’ve read this submit and if I could I wish to suggest
you few interesting issues or advice. Maybe you could
write next articles regarding this article. I wish to read
more issues about it!
Eddie Jett
11 May 2023I’d like to find out more? I’d like to find out some additional information.
Barry Lavanway
11 May 2023It is perfect time to make some plans for the future
and it is time to be happy. I’ve read this post
and if I could I desire to suggest you some interesting things or advice.
Maybe you can write next articles referring
to this article. I wish to read even more things about
it!
George Parrish
11 May 2023Hi to every , for the reason that I am really eager of reading this blog’s post
to be updated on a regular basis. It consists of fastidious data.
Helen Jinzo
11 May 2023I am now not sure the place you’re getting your info, but good topic.
I needs to spend a while learning more or working
out more. Thanks for magnificent information I was searching for this information for my mission.
Michael Harris
11 May 2023Way cool! Some very valid points! I appreciate you writing this write-up plus
the rest of the site is very good.
Lee Fitts
11 May 2023I’ve been browsing online more than three hours these days, but
I never discovered any interesting article like yours.
It is beautiful price enough for me. Personally, if all webmasters and bloggers
made good content material as you probably did, the net will likely be a lot more helpful than ever before.
Sonya Passmore
11 May 2023I have been surfing online more than three hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all webmasters and bloggers made
good content as you did, the web will be a lot more useful than ever before.
Clomqq
11 May 2023mebendazole 100mg sale tretinoin gel for sale purchase tadalis pills
Ndbafb
11 May 2023metronidazole 400mg ca flagyl pills keflex 250mg oral
Sluckk
12 May 2023avana 200mg ca buy diclofenac generic voltaren cheap
gate borsası
13 May 2023At the beginning, I was still puzzled. Since I read your article, I have been very impressed. It has provided a lot of innovative ideas for my thesis related to gate.io. Thank u. But I still have some doubts, can you help me? Thanks.
Cnmmlc
13 May 2023how to get clindamycin without a prescription sildenafil 100mg usa order sildenafil 100mg online cheap
Jtenpt
14 May 2023order indomethacin 50mg capsule cefixime generic order cefixime 200mg sale
Yqsmcu
15 May 2023generic tamoxifen 20mg order budesonide generic order ceftin 500mg online
Створити особистий акаунт
15 May 2023Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/uk-UA/register-person?ref=WTOZ531Y
Ermopn
15 May 2023oral amoxicillin 500mg buy trimox sale clarithromycin 500mg oral
AlergeFug
16 May 2023is cialis generic After returning to his senses, he looked at Murong Yanzhao, and said in a concerned tone, The great Han has entered a critical moment of unification, and the affairs of the state have been so complicated recently, and I still rely on a capable minister like Qing, who is both civil and military, to help me and share the burden for me As a unprotected sex with birth control pills minister, Murong Yanzhao s political literacy has also improved erectile dysfunction drugs free sample Stay Hard Erection Pills to a certain level
binance註冊
17 May 2023Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.com/zh-TC/register?ref=WTOZ531Y
sop
10 Jul 20234. Suma wygranych z Darmowych Spinów zostanie automatycznie dodana bezpośrednio do konta gracza jako środki bonusowe. Darmowe Spiny muszą zostać obrócone 15 razy, zanim nastąpi wymiana na środki realne i będzie możliwa ich wypłata. Jeżeli nie chcesz grać za większe kwoty, z pewnością wybierzesz odpowiednie dla siebie kasyno online. Wybrać kasyno z niskim depozytem nie jest już problemem, więc po co inwestować wielkie sumy, jeżeli można wygrać równie wysokie wygrane, inwestując kilka złotych. W ten sposób można pozwolić sobie także na częstsze granie, bez uszczerbku dla finansów. Betinia nie wymaga wielkiej znajomości branży kasynowej. Wystarczy 45 zł, by dołączyć do gry. Kasyno jest dostępne w polskiej wersji językowej.
http://www.daonmindclinic.com/bbs/board.php?bo_table=free&wr_id=43453
Aby zostać klientem, musisz wykonać kilka prostych kroków. Oto przewodnik, który pomoże Ci łatwo ukończyć pełną rejestrację: Wysoka kwota bonusów pozwala zdobyć dodatkową gotówkę na grę, co może mieć szczególne znaczenie dla nowych graczy. Przy niższych wpłatach takich jak 10 zł istotne jest jednak też, czy gracze mogą w ogóle skorzystać z premii depozytowych i darmowych spinów. Weryfikujemy również, jakie kwoty obrotu są wymagane w kasyno minimalny depozyt 10 zł do odebrania bonusowej gotówki na konto. Nazywam się Stanisław Szymański. Pracuję jako redaktor naczelna dla jednej z najlepszych stron internetowych poświęconych kasynom online – kasynopolska10. Studiowałem w Warszawska Wyższa Szkoła Informatyki. Przed dołączeniem do KasynoPolska10 pracowałem jako analityk nisz hazardowych. Całe życie mieszkam w Warsaw i od kilku lat redaguję i piszę teksty związane z kasynem, automaty do gier itp. Myślę, że nasza strona będzie dla Ciebie przydatna!