

The Questions That You May Be Asked During a Hadoop Interview
You must know that Hadoop experts are those who are having the most job opportunity nowadays. In order to be prepared for such an interview, you must be having a go through this article so that you are aware of the Hadoop Interview Questions. It is always better to be prepared for an interview rather than facing an awkward situation during the interview. Knowing the nature of questions that may be asked will make you confident about facing the interview and in the end, having the job. Continue reading and know the probable questions to make yourself suitable to be chosen for the offered job.
Let us see a number of the questions that you may face through such an interview. We have made sure to include the probable answers also so after understanding through this you feel that you are more equipped than the being who will be interviewing you.
What is Big Data and what are five V’s?
You may be thinking of what should be the answer to this question which has been asked. The answer should be that Big Data is that type of collection of data that is large and complex. Being such complex and large the processing of such kind of data is difficult using database management tools or other tools that are used for processing data. It is such that it is difficult to confine, curate, store up, look for, distribute, transmit, analyze, and to envisage. Big data has made opportunities for companies so that they can work efficiently with this nature of data.
Now let us see what you should say about the 5 V’s. The 5 V’s are:
- Volume: It represents the quantity of data that is ever-expanding at an amazing rate in Petabytes and Exabytes.
- Velocity: It is the fast rate at which these data increases. It is such a rate that if you think today then the data that you had yesterday is obsolete. It is also seen that social media is the biggest contributor to such data.
- Variety: These data are in various formats or varieties. They may be in the format of videos, CSV or audios. It may be in any other kind of format also.
- Veracity: It is the doubt that is related to this nature of data. This happens due to the inconsistency and the incompleteness of the data. You cannot believe in the data sometimes and that is what is all about veracity.
- Value: It is useless to have such data unless we can have trust with it. That is what value is all about.
So, what do you feel now about the answer to this question? You must be confident that you will be able to answer it.
What is Hadoop and what are the components that make it up?
This may be the second question that may be asked to you when you sit for this nature of an interview. Let us prepare ourselves for this question so that as asked we can answer that and impress the interviewer.
It is seen that when Big Data started causing problems a solution was evolved through Apache Hadoop. It is software that gives us access to various natures of tools and services by means of which we can work with Big Data. Using these tools and services we can stock up and process Big Data. If we use the traditional system then we cannot efficiently analyze this nature of data and derive the results which are beneficial to us but using this innovative technology we can do that in the most efficient manner.
So, prepared with the answer and having the confidence to succeed.
What is the meaning of HDFS and YARN?
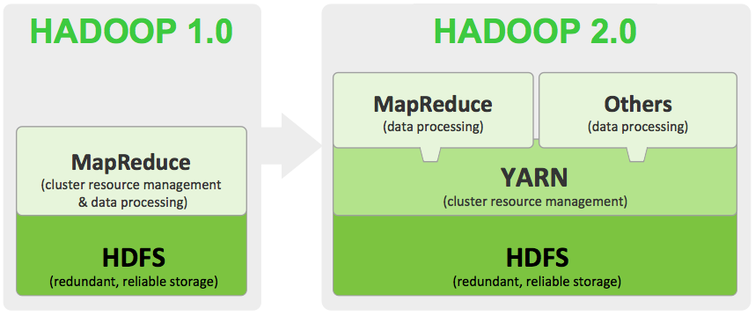
This may be another one from the set of Hadoop Interview Questions that you may be asked. The full form of HDFS is Hadoop Distributed File System and this is the storage place of Hadoop. It is the unit that is responsible for the storage and maintenance of data. The data are saved as blocks in an environment that are distributed. The topology that is followed in this method is master and slave. There are two components of this nature of storage. They are:
- Name node
- Data node
Let us now know about YARN, the full form is Yet Another Resource Negotiator. This is where the entire processing is done and this helps to administer assets and provides an implementation setting to the processes. Over here also there are two components. They are:
- Resource Manager
- Node Manager
So, what are you feeling about yourself? Getting confident, isn’t it? Continue reading and you will be able to know about various other questions that you may be asked during the interview. It is certain that after finishing reading you will know more than your interviewer and will be certain to have the job.
What are the various Hadoop daemons and what are their roles?
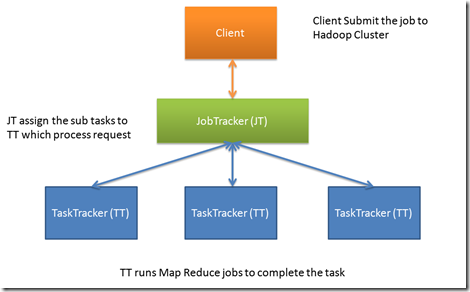
You may be confused about how to answer this question. You are confused as you have to tell about a lot of things to give a proper answer. There is nothing to be confused about. Tell about the Hadoop demons like Name Node, Data Node, and Secondary Name Node and then tell about the YARN daemons which are Resource Manager and Node Manager and then if the interviewer does not ask the next question explain about Job History Server. Now let us know what exactly has to be told.
- Name Node: It is the node that is a master in nature and is accountable for up keeping the metadata of all the documents that are in the data. It has the knowledge about blocks, that creates a file, and also about the location of those blocks in the cluster.
- Data node: It is the node that is a slave in nature and it is that which retains the actual data.
- Secondary Name Node: It at regular intervals assimilates the changes with the FsImage, currently in the Name Node. It stores the tailored FsImage into unrelenting storage space, and that can be used when there is a failure of the Name Node.
- Resource Manager: It is the essential authority that tackles all the resources and calendar applications that are running on top of YARN.
- Node Manager: It is the one that is responsible for the initiation of the application’s space, adjusting their resource usage and letting the Resource Manager know about it.
- Job History Server: It keeps track of the information regarding Map Reduce jobs after the termination of Application Master.
Are you confused now also? You should not be, this is the answer that you should give to impress the interviewer. It may so happen that after you answer this question you may not be asked further but then also let us see some other questions so as to be prepared completely.
What is the comparison between HDFS and NAS?
Another bombshell, are you looking at this question in this manner. There is nothing to worry about just continuing reading and you will understand what you need to answer. First, you have to explain HDFS and NAS and then you can compare the features that they are made of.
- NAS is a data storage server that is connected to a network of computers that enables the assorted group of clientele access to data. This can be hardware and also can be software. Now HDFS which is a file system distributed in nature and it stores the required data in commodity hardware.
- Data stored in HDFS is distributed along all the computers that are in the network while in NAS the storage is made in hardware is specially dedicated for this purpose.
- Both of them work using MapReduce Program but in HDFS computation is associated with the data and in NAS the data is kept separate from the computation.
- HDFS is cost-effective as there is the usage of commodity hardware but NAS is costly comparatively as it uses a dedicated server for this purpose.
I think after reading this answer you can clearly explain to your interviewer why you should be the one who should be given the job and no one else.
What is the difference between active and passive Name Nodes?
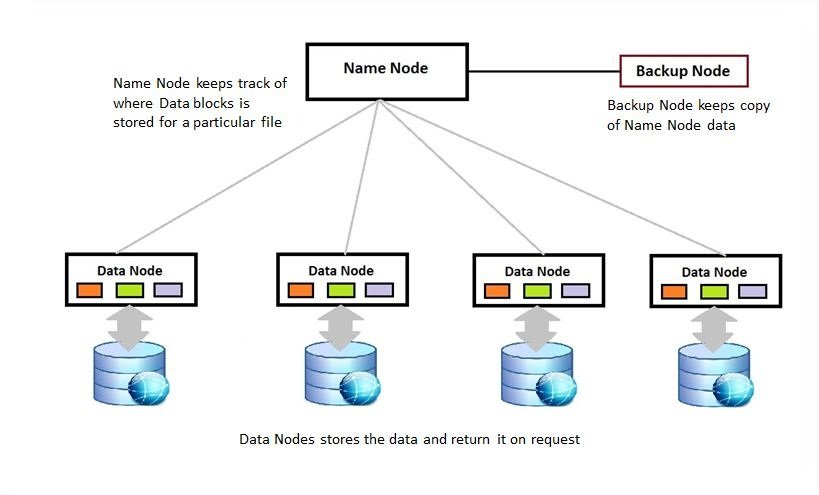
Ahh! A simple question that has been asked. But then also let us know the answer so that we do not get confused or be overconfident at any stage. The answer to this question is:
If the architecture that we are using is of high end then there are two nodes namely, Active Name Node and the Passive Name Node.
If the Name Nodes works in the clusters then it is the Active one, whereas if it works in the standby mode then it is the Passive one. The utility of having two Nodes is that upon the failure of one the other can take over.
What is the most common task of a Hadoop administrator?
Do, you know the answer? You must be knowing the answer but for the benefit of others let us know the answer. The most common task of such an administrator is adding and removing the Data Nodes in a cluster. There are definitely reasons for this task. Surely, there are two reasons. As Hadoop uses commodity hardware there are frequent crashes which happen in such a cluster, this is one of the reasons for this nature of task for an administrator and the other reason is the ease with which it can be escalated along with the increase of data.
What is the role of jps command?
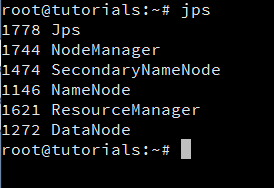
This may be the next question from the set of Hadoop Interview Questions that you are asked. The answer is quite simple. It gives you information regarding daemon status. It lets you know the status of all the Nodes along with those of Job and task tracker.
Mention the names of the modes in which Hadoop can be run?
This is also a simple question to answer but it is always advisable to be prepared with simple questions also. The three modes in which Hadoop can be run are:
- Mode which is standalone in nature
- Mode which is Pseudo distributed can also be a way of running Hadoop
- Again you can have a fully distributed mode for running Hadoop
What are the input formats by means of which you can operate Hadoop?
It is always seen that those who are ready with minute answers wins at the interview table. You may be thinking that is this that nature of the question which can be asked in an interview. You never know, this may be the one which can lead your path to success. So, be prepared with this also. The answer to this one is that there are three input formats that can be used in Hadoop. They are:
- Text Input
- Key value Input and
- Sequence File Input
Do you know the job role of Job Tracker? If yes then explain.
This may be the next one which you are asked. The answer is simple but it should be answered in sequence so that the role can be explained at the same time.
The job roles of Job Tracker are the following:
- It accepts works from customers
- As it accepts the job it establishes a communication with the Name node to determine where the data is located.
- It then tries to find out which Task Tracker node has available slots
- It then allocates the job to that particular Task Tracker Node and also determines the progress of the job as it is done.
Explain Heartbeat in Hadoop?

You may be thinking that the interviewer has gone mad. You may be thinking heartbeat and that too of Hadoop. Yes, that is true, it too has a heartbeat. Let us know what it is. Heartbeat is the nature of signal which is used between two nodes namely data and name and also between two trackers namely job and task. If it is seen that there is no response from a name or task node then it can be ascertained that there is some problem with them.
Explain Hadoop streaming?
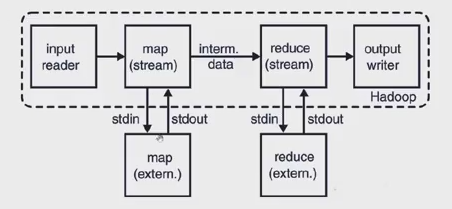
You may know the answer as these are basics that you must know in order to have the job and that is the reason why these are asked at interviews. They want to make sure that you have the basic clear in your mind.
The answer to this basic question is that streaming is that which helps you to generate and work with map job. This is the nature of generic API which allows any programs written in any language to be utilized in the mapper that is in Hadoop.
Do you know the method to debug Hadoop code?
The answer to this question must be certainly yes. There are many methods by means of which you can debug a Hadoop code. There are some popular methods for doing so. The most popular methods are:
- Counters to be used
- By using the interface that is presented by Hadoop
The method is simple and can be easily done. So, you are ready with the answer and can completely be confident with the answers that you give.
Explain the difference between other tools that process data and Hadoop?
Hadoop has a unique feature that is not available in other tools that process data. Hadoop gives you the opportunity to increase or decrease the mapper number depending on the quantity of the data. This makes the tool to be the one that is used by many.
Explain distributed cache?
This is the facility that is provided by the Map-Reduce feature. It is that which makes available the files that are needed to work upon at the time when a job is executed.
What is the nature of the storage of data used by Hadoop?
The nature of storage that is used by Hadoop is HBase.
Explain the relationship that is between job and task?
You may be thinking they both are similar. No, they are not in Hadoop. A job in Hadoop is divided into parts which are called tasks.
There may be lots of questions that can be asked in such an interview. But these are the ones which are the ones which are generally asked.
Being prepared with such type of Hadoop Interview Questions you will have the necessary confidence and mindset up so that you are the one who will be selected for the job. Try to face the interviewer with the level of confidence so that they feel that you know all about Hadoop. While answering a single question give the answer in such a form that all is explained about that question.
So, take the next opportunity that you have to appear at such an interview and have success which is knocking at your door.



Jywdwv
23 Feb 2023cost digoxin 250mg buy digoxin 250 mg without prescription order molnunat online cheap
Mmpqzw
24 Feb 2023buy generic diamox 250mg brand diamox 250mg order azathioprine pills
Qxcgvc
25 Feb 2023order digoxin 250 mg digoxin order molnunat pill
Content In One Click
26 Feb 2023Artificial intelligence creates content for the site, no worse than a copywriter, you can also use it to write articles. 100% uniqueness,5-day free trial of Pro Plan :). Click Here:👉 https://bit.ly/3lwPi7J
Content In One Click
26 Feb 2023Artificial intelligence creates content for the site, no worse than a copywriter, you can also use it to write articles. 100% uniqueness,5-day free trial of Pro Plan :). Click Here:👉 https://bit.ly/3lwPi7J
Lgnobz
28 Feb 2023buy carvedilol 25mg pill buy coreg sale order generic elavil 10mg
Omsskr
28 Feb 2023order amoxil 1000mg for sale buy generic stromectol stromectol how much it cost
Qusnmo
1 Mar 2023buy alendronate 35mg furadantin 100mg brand motrin online buy
Atgeqe
1 Mar 2023dapoxetine 60mg generic domperidone for sale online order domperidone pills
Lajlaj
3 Mar 2023nortriptyline 25 mg usa buy panadol buy paxil sale
Xgprpn
3 Mar 2023indomethacin capsule buy flomax 0.4mg for sale cenforce 50mg sale
Faryef
4 Mar 2023buy famotidine 40mg pill famotidine 40mg over the counter buy remeron 15mg without prescription
Tatmfr
5 Mar 2023doxycycline price buy doxycycline 200mg generic methylprednisolone 16mg tablet
Ayoiza
6 Mar 2023buy ropinirole 2mg online cheap buy requip 1mg for sale cheap labetalol
Vdbjvo
7 Mar 2023purchase tricor without prescription tricor 200mg price oral sildenafil 100mg
Vjmzps
8 Mar 2023cost nexium 40mg brand esomeprazole 20mg order furosemide online cheap
Mhtpwi
9 Mar 2023cheap generic cialis Cialis prescriptions cheap sildenafil pill
Gpstud
10 Mar 2023minocycline 100mg brand purchase terazosin without prescription hytrin for sale
Swdbek
10 Mar 2023purchase cialis online Cialis online store the best ed pill
Lsymjh
12 Mar 2023glucophage 500mg without prescription glucophage 500mg usa buy tamoxifen pill
Qnwpvw
12 Mar 2023buy provigil 100mg sale order provigil 100mg sale buy phenergan
Qhopan
13 Mar 2023serophene brand clomiphene 100mg pill buy prednisolone 5mg pill
Ckzoky
14 Mar 2023order prednisone 10mg pills order isotretinoin sale buy generic amoxicillin 250mg
Yuasjk
15 Mar 2023generic accutane 40mg order ampicillin online ampicillin online
Ykkvdd
16 Mar 2023sildenafil 100mg cheap order fildena online buy finasteride generic
Dkqcux
18 Mar 2023order zofran 4mg for sale buy bactrim 960mg generic buy generic sulfamethoxazole
Xwlfnb
19 Mar 2023accutane 40mg ca absorica order online azithromycin 500mg without prescription
Gvbwcg
20 Mar 2023albuterol generic purchase levothyroxine pills buy amoxiclav online cheap
Xvolgt
22 Mar 2023order modafinil 200mg generic metoprolol 50mg over the counter lopressor 100mg usa
Cqesvn
24 Mar 2023purchase dutasteride online cheap order xenical 60mg online buy generic xenical
Trisdz
24 Mar 2023purchase vibra-tabs generic buy levitra 10mg generic buy generic acyclovir 800mg
Zypzuw
26 Mar 2023order generic imuran micardis drug buy naproxen 500mg sale
Bajfos
27 Mar 2023oxybutynin without prescription oral prograf 1mg order oxcarbazepine 600mg online
Iauarp
28 Mar 2023omnicef medication protonix 20mg oral protonix 20mg pill
Ojjsdv
29 Mar 2023simvastatin online order zocor 20mg generic purchase sildalis
Bxsizz
29 Mar 2023dapsone 100mg drug asacol drug order atenolol 100mg sale
Pifbfz
31 Mar 2023buy alfuzosin for sale buy diltiazem online diltiazem order online
Zxheic
31 Mar 2023viagra 100mg cost sildenafil 50mg cialis coupon walmart
Diwjgc
2 Apr 2023promethazine price purchase phenergan without prescription order cialis 5mg pills
baccaratsite
2 Apr 2023The assignment submission period was over and I was nervous, baccaratsite and I am very happy to see your post just in time and it was a great help. Thank you ! Leave your blog address below. Please visit me anytime.
Ezhkrm
2 Apr 2023order ezetimibe pill cost methotrexate 5mg order methotrexate 5mg without prescription
Huguny
4 Apr 2023levaquin 250mg price buy generic actigall 300mg order bupropion without prescription
binance margin demo
4 Apr 2023I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Ztbgak
5 Apr 2023buy warfarin cheap purchase allopurinol pill order zyloprim 100mg online cheap
levitra from canadian pharmacy
6 Apr 2023canadian pharmacy us
no prescription drugs canada
7 Apr 2023buy meds online
Ljeyxs
8 Apr 2023buy zyrtec 10mg without prescription order zoloft 100mg online order sertraline 50mg pills
Ilcolz
8 Apr 2023order cenforce 50mg pills cenforce 100mg oral purchase glycomet for sale
online pharmacy prescription
8 Apr 2023canadian pharmacy world
Yirhos
9 Apr 2023lexapro 10mg cost lexapro online buy revia canada
canadian online pharmacies legitimate
9 Apr 2023canada pharmaceuticals online
drugs online
9 Apr 2023aarp approved canadian online pharmacies
Kaqefb
10 Apr 2023order lipitor 10mg generic buy viagra 100mg online sildenafil 100mg cheap
Ywipev
10 Apr 2023femara 2.5 mg brand femara 2.5mg us buy viagra sale
canadiandrugstore.com
10 Apr 2023canadian pharmacies review
no rx online pharmacy
11 Apr 2023online pharmacies canadian
Nbslua
12 Apr 2023order tadalafil 40mg generic buy cialis 20mg online cheap buy ed pills uk
Csrzms
12 Apr 2023order tadalafil 40mg online order cialis 40mg generic where can i buy ed pills
Zjkjkb
13 Apr 2023buy modafinil generic modafinil usa purchase prednisone sale
Gicgxo
14 Apr 2023how to buy amoxil buy zithromax medication prednisolone medication
canadian pharmacy presription and meds
14 Apr 2023canadian pharmacy pain meds
reliable mexican pharmacies
14 Apr 2023legal online pharmacies
legitimate canadian pharmacies
15 Apr 2023canadian pharcharmy reviews
Uyzhhg
15 Apr 2023absorica pills order isotretinoin 40mg online zithromax uk
Pvtkkz
16 Apr 2023neurontin 100mg over the counter neurontin 600mg without prescription doxycycline 200mg generic
Kzmrrm
17 Apr 2023buy albuterol 4mg generic augmentin 375mg pills order synthroid pill
Çanakkale Sakso Çeken Escort
17 Apr 2023Çanakkale escort bayanlar ile sevgili tadında özel bir beraberlik yaşamak sizin en doğal hakkınızdır. Bayanlar seksüel dürtülerinin tatmininden başka bir şey istemeyen bir erkekle tanışmak talip titizler. Bir erkeği heyecanlandırmayı ve sonsuz şehvetini hissetmeyi seviyorlar. Seni baştan çıkarmaya ve bunun için en seksi iç çamaşırlarını giymeye bayılacaklar. Eğer istersen, beraberliğinizin başında sana hoş anlar yaşatırlar. Yaramaz bir randevu için onlarla nerede buluşmak istediğin sana kalmış. Seni en çok nasıl azdırabilirler merak ediyoruz? Ama kıyafetlilerini öyle bir seçeceğine güvenilir olabilirsiniz ki, evvela göğüslerine mi yoksa popolarına mı bakacağınızı bilemezsiniz. En iyi parçanın neye benzediğini görmek için aslında heyecanlılar. Bir penisi öyle bir şekilde şımartmak bayanları çok heyecanlandırıyor.
Ordu Garaj Escort
17 Apr 2023Sık sık yerde olan ve herhangi bir rastgele zayıflık göstermesine izin verilmeyen adamlardan hoşlanır mısınız? Zıtlık uğruna, aslında kendinizi rahat ettirebilmek ve rahatlayabilmek güzel olmaz mıydı? Birçok alanda en yüksek performansı alıyorsunuz, bu yüzden günlük hayatınızı unutup kendinizi şımartmak için bana gelmeniz sizin için uygun. Başarısız ve zamanın baskısı olmadan, cinsel <Ordu escort hizmetleri bu kadınların uzmanlık alanıdır. Birçok erkek tatlı konuşmalarını çok seksi bulur ve buna doyamaz. Bu arada, yatakta çok azgın değillerse, ateşli fotoğraflarını bile burada göremezsiniz. Evet, mutlu ve neşeli insanlar olduklarını söyleyebiliriz.
canadian pharmacy non prescription
17 Apr 2023my canadian pharmacy viagra
online prescriptions
18 Apr 2023canadian online pharmacies
Rualfx
18 Apr 2023prednisolone us neurontin 100mg ca furosemide 100mg pill
Welquf
18 Apr 2023order generic clomiphene levitra generic buy plaquenil 400mg for sale
Dgwqks
19 Apr 2023vibra-tabs usa augmentin 625mg over the counter buy augmentin generic
Zyravw
20 Apr 2023atenolol 100mg pill buy atenolol online letrozole online
prescription without a doctor's prescription
21 Apr 2023cheapest viagra canadian pharmacy
Eqhxdc
21 Apr 2023order levoxyl generic purchase levothroid without prescription vardenafil sale
Hvtbbt
21 Apr 2023generic albendazole 400mg buy cheap generic albendazole order provera 5mg pill
best canadian pharcharmy online
21 Apr 2023family discount pharmacy
buy online prescription drugs
22 Apr 2023canadapharmacyonline com
Gkfpaa
22 Apr 2023glycomet 500mg canada purchase amlodipine generic order norvasc 10mg pill
Izsnwz
22 Apr 2023buy praziquantel 600 mg online order cyproheptadine online cheap buy generic periactin over the counter
canadian mail order pharmacies to usa
23 Apr 2023best online mexican pharmacy
buy drugs canada
23 Apr 2023trusted canadian online pharmacy
No deposit bonus
23 Apr 2023No deposit bonus from https://zkasin0.site connect your wallet and enter promo code [3wedfW234] and get 0.7 eth + 100 free spins, Withdrawal without limits
Moyyvs
23 Apr 2023buy lisinopril tablets order prilosec 10mg online buy metoprolol 100mg sale
Wbzwem
23 Apr 2023pregabalin 150mg ca loratadine over the counter priligy 60mg price
Mjbohc
24 Apr 2023order methotrexate 10mg without prescription buy generic methotrexate 2.5mg buy metoclopramide generic
Jfudlh
25 Apr 2023xenical 120mg uk buy orlistat 60mg generic order zyloprim 300mg sale
Gfixey
26 Apr 2023buy losartan cheap topiramate 100mg oral purchase topamax online
Zhygco
26 Apr 2023rosuvastatin 10mg drug rosuvastatin 10mg price buy domperidone 10mg generic
Zepyms
28 Apr 2023imitrex 25mg pills buy levaquin 500mg without prescription order dutasteride generic
Ovtkdv
28 Apr 2023buy sumycin without a prescription cost sumycin 500mg baclofen 25mg sale
Zhnbwq
29 Apr 2023purchase toradol sale order inderal 20mg online cheap inderal 10mg drug
Tyjujr
29 Apr 2023zantac 150mg uk meloxicam 15mg usa order celecoxib 200mg without prescription
Ygppoq
30 Apr 2023plavix 75mg sale buy plavix pills purchase nizoral without prescription
Wugiek
1 May 2023order tamsulosin 0.2mg generic aldactone price buy aldactone online
pariapp
1 May 2023Как и другие легальные букмекеры, ПАРИ постарались сделать своих клиентов еще более счастливыми. Поэтому были запущены собственная мобильная версия сайта, а также приложения для смартфонов на Андроид и IOS. Они позволяют постоянно иметь доступ к личному кабинету игрового счета, а также возможность заключать пари, где бы не находился пользователь. Для использования потребуется лишь мобильный телефон и наличие доступа в интернет.
Как скачать мобильное приложение БК ПАРИ. [url=https://www.vseprosport.ru/reyting-bukmekerov/pari-match-mobile-app]пари скачать[/url]
[url=https://www.alpha-soft.al/en/infrastructure/marketing/]Скачать Пари на Андроид — мобильное приложение букмекерской конторы | ВсеПроСпорт.ру[/url] f773854
Заходим на официальный сайт БК Пари, нажать в левом верхнем углу на три полоски, В открывшемся меню выбираем “Приложения”, Прокрутить страницу и выбрать удобный способ скачивания. Выбрав android начнется скачивание apk файла,Находим в загрузках скаченный файл и кликнуть кнопку “Установить”,
Приложение установлено, нажать “Открыть”.
Виды приложений PARI.ru
Смартфоны последних поколений, как правило, работают на базах iOS и Android. Этот момент учитывался разработчиками и были созданы два вида приложения, каждый из которых подходит на ту или иную платформу. Также, чтобы владельцы более старых моделей телефонов не испытывали дискомфорта, создали мобильную версию главного сайта. Букмекерская контора ПАРИ рассчитывает на то, что ее пользователи будут осуществлять свои ставки не только с личных персональных компьютеров или ноутбуков, но и с помощью мобильных гаджетов и планшетов.
Мобильной версии сайта следует отдать должное внимание, поскольку она максимальна проста и удобна в использовании. Размеры всех кнопок и шрифтов адаптивны, что позволяет производить автоматическое изменение под каждый размер экрана. Для телефонов, работающих на платформах: Java, symbian и т.п рекомендуется использовать специальных браузер Opera mini. Он позволяет сделать открытие страниц более удобным и быстрым, даже при плохом соединении с интернетом.
Оценка приложения – 4/5
Говорить о преимуществах и недостатках букмекерской конторы можно не так долго, поскольку она практически не отличается от конкурентов. Явных недостатков, доставляющих большие неудобства, попросту не имеется. Важное внимание следует уделить мобильной версии сайта, которая по праву считается одной из самых лучших, среди всех существующих легальных букмекерских контор в Российской Федерации. Также не следует забывать о таких нюансах, как:
1. Функционал – рассказывать о нем много смысла нет, поскольку он полностью идентичен многим конторам по приему ставок. Клиенты могут без проблем использовать все доступные функции, в независимости с какого устройство осуществляется вход в игровой счет.
Более удобный интерфейс адаптированный для мобильных устройств.
2. Графика – простая и понятная страница мобильной версии, а также минимизированное и удобное меню приложения, позволят научиться совершать ставки с телефона. Процесс будет проходить быстрее у тех, кто до этого был клиентом нелегального PARI.
Возможность добавить в избранное любимый чемпионат, лигу и дивизион, а также самый ожидаемый матч.
3. Финансовый вопрос – быстрый вывод денег,вносить и снимать средства с игрового счета может исключительно его владелец. Для этого можно использовать различные банковские карты, электронный кошелек Киви или Вебмани, а также Яндекс деньги.
Возможность делать ставки в режиме Live.
4. Инструменты – в этом пункте следует выделить наличие большого количества видеотрансляций. Также можно сказать о простом переходе в разделы лайв и возможности смотреть расписание предстоящих игр.
Быстрая работа, возможность поиска событий.
5. Ставки – большим плюсом у ПАРИ является широкий выбор ставок. Благодаря внушительному списку видов спорта, пользователь сможет найти что-то наиболее подходящее именно ему.
6. Прямые трансляции – на сайте букмекера есть текстовые и видеотрансляции избранных событий.
Как скачать приложение ПАРИ для IOS / Android
Для скачивания приложений на смартфон, человеку потребуется всего лишь пройти по ссылкам. На официальном сайте имеется специальный раздел, который носит название: “Mobile”. Перейдя в него, можно скачать приложение на платформы Андроид и АйОС. Кроме этого, обладателям телефонов и планшетов от Apple, можно найти данную программу в App Store. Чтобы значительно сократить процесс поиска приложения или перехода на сайт, это можно сделать по ссылкам, представленным ниже:
[url=https://www.vseprosport.ru/away/114]iOS приложение[/url]
[url=https://www.vseprosport.ru/away/114]Приложение на Android[/url]
Следует отметить тот факт, что загрузка этих приложений будет производиться с официального сайта букмекера. Таким образом можно обезопасить свое устройство от заражения нежелательными вирусными программами.
Обзор приложения ПАРИ. [url=https://www.vseprosport.ru/reyting-bukmekerov/pari-match-mobile-app]пари скачать[/url]
Более подробно рассмотрев приложение, пользователь сможет научиться быстро перемещаться в необходимые разделы, поскольку навигация по нему достаточно простая. Разработчики постарались сделать все как можно проще и удобнее, поскольку далеко не все имеют возможность пользоваться сложными приложениями.
Первое, что увидит пользователь после установки — это страница авторизации. Для заключения пари в БК ПАРИ необходимо иметь собственный игровой счет, который можно зарегистрировать на официальном сайте или через мобильное приложение. После того, как доступ к игровому счету был получен, можно приступать к непосредственному использованию.
Для внесения и снятия средств не потребуется заходить с компьютера, поскольку эти функции имеются в приложении. Говоря о способах для этого, то они ничем не отличаются от компьютерной версии сайта. Ставки можно заключать как в виде одинарных, так и экспрессами.
Основные особенности мобильной версии ПАРИ
Как таковых особенностей у приложения не имеется, поскольку оно является середняком из имеющихся легальных букмекерских контор. Как уже отмечалось ранее, приложение имеет свои преимущества и недостатки, но следует отметить, что это далеко не самый плохой вариант. Единственный нюанс, который может тревожить пользователей — это отсутствие возможности следить за матчами в режиме реального времени через приложение.
Часто задаваемые вопросы .
1. Почему не устанавливается приложение для Андроид?
Возможно, необходимо просто разрешить скачивание и установку приложений из неизвестных источников. Это осуществляется в разделе настройки, потом переходим в приложения и в соответствующем поле включаем данную функцию.
2. Какова минимальная сумма пополнения?
Минимальная сумма пополнения 100 Российских рублей.
[url=http://jety98.cz/projekty_podpora_mladych.php]Скачать Пари на Андроид — мобильное приложение букмекерской конторы | ВсеПроСпорт.ру[/url]
Qipnxt
1 May 2023purchase duloxetine online cheap buy cheap generic duloxetine nootropil 800 mg tablet
canadian drugs cialis
2 May 2023internet pharmacy no prior prescription
Qprerr
2 May 2023order betamethasone 20 gm creams betamethasone 20 gm cost itraconazole 100mg without prescription
Gjxcwb
3 May 2023buy ipratropium without prescription buy linezolid 600mg online cheap zyvox 600mg
Hdreur
3 May 2023progesterone where to buy purchase zyprexa zyprexa online
Kwshhw
5 May 2023oral bystolic 20mg order valsartan pill brand clozaril
Fmetmf
5 May 2023nateglinide 120 mg for sale nateglinide medication candesartan ca
vaioasob
6 May 2023На сайте https://numerolog56.ru/ вы сможете узнать интересную, познавательную информацию о нумерологии, различных болезнях, когда и за что они даются, про планеты и варны. Имеется информация о деньгах, финансах, карме, матрице судьбы, персональных данных и многом другом. Вы обязательно отыщите такую тему, которая будет интересна. Важно то, что статьи написаны экспертами – они публикуют только ту информацию, в которой разбираются сами и желают поделиться ей с вами. Все материалы содержательные, информативные, а потому вы почерпнете много нового.
Shzrou
6 May 2023simvastatin 20mg brand viagra mail order usa cost sildenafil
best online pharmacy without prescription
6 May 2023no prescription canadian pharmacies
Jnzhwp
7 May 2023buy tegretol 200mg online lincocin 500mg pill buy lincomycin pills for sale
totosite
8 May 2023From some point on, I am preparing to build my site while browsing various sites. It is now somewhat completed. If you are interested, please come to play with totosite !!
Qphuhr
8 May 2023order cefadroxil generic buy generic finasteride order propecia 1mg for sale
Zqfrrw
8 May 2023buy tadalafil 10mg online tadalafil 10mg cost buy generic viagra 50mg
Tzfgtz
9 May 2023buy diflucan cheap cipro 1000mg over the counter buy generic cipro online
canadian drugstore cialis
10 May 2023canadian prescription pharmacy
heets fiyat
10 May 2023en uygun fiyatlardan heets satın alın ve sizde heets sigara sahibi olun
Hamkko
11 May 2023buy generic estrace 2mg lamictal 50mg tablet prazosin online order
Ynwmcb
11 May 2023buy generic flagyl 200mg metronidazole for sale online buy generic cephalexin
Swmxoz
12 May 2023order mebendazole 100mg online cheap buy mebendazole 100mg sale buy tadalis generic
Jjobvz
13 May 2023cheap cleocin 300mg order erythromycin buy sildenafil 50mg for sale
Ofakge
14 May 2023order avana 100mg online avana 100mg us cambia ca
Efivsn
14 May 2023buy nolvadex for sale tamoxifen 20mg pills cefuroxime 500mg uk
Rnuwcy
15 May 2023cheap indocin 50mg indomethacin online suprax 100mg sale
Eeqiex
16 May 2023careprost order online order bimatoprost for sale where to buy desyrel without a prescription
Kqgvhm
17 May 2023trimox us oral amoxicillin 250mg biaxin 250mg ca
Geraldhak
18 Feb 2024[center][size=5][b]Фасовщик масла М6-АРМ FASA 500 гр инв.11901 на Втормаш[/b][/size][/center]
[center][img]https://vtormash.ru/img/upload/itemsdop-1702899239-fe7563f0.jpg[/img][/center]
[center][color=green]Описание:[/color] Фасовщик масла М6-АРМ FASA 500 гр инв.11901 — это высокоточное оборудование, спроектированное для эффективной фасовки масла в удобные и практичные упаковки. С этим фасовщиком вы обеспечите быстрое и точное дозирование продукции, сохраняя при этом ее качество и безопасность.[/center]
[color=blue][b]Характеристики:[/b][/color]
1. [b]Тип:[/b] Фасовщик масла М6-АРМ FASA 500 гр
2. [b]Инвентарный номер:[/b] 11901
3. [b]Производитель:[/b] Известный бренд FASA, гарантия качества.
4. [b]Объем фасовки:[/b] 500 гр, идеально подходит для различных размеров упаковок.
5. [b]Точность дозировки:[/b] Высокоточный механизм для точной фасовки масла.
6. [b]Материал:[/b] Прочные и безопасные материалы для контакта с продукцией.
7. [b]Простота обслуживания:[/b] Легкость в управлении и обслуживании.
[center][color=red][b]Где приобрести:[/b][/color] [color=red]Посетите [url=https://vtormash.ru/katalog/fasovochnye-avtomaty-masla/fasovshhik-masla-m6-arm-fasa-500-gr-inv-11901][/color]
[center][size=5][b]Ёмкость В2-ОМВ 6,3м? инв.10145 на Втормаш[/b][/size][/center]
[center][img]https://vtormash.ru/img/upload/itemsdop-1702560522-5050596b.jpg[/img][/center]
[center][color=green]Описание:[/color] Промышленная ёмкость В2-ОМВ 6,3м? инв.10145 представляет собой надежное и емкое решение для хранения и транспортировки различных жидких продуктов. С ее помощью вы сможете обеспечить безопасное и эффективное сохранение вашей продукции.[/center]
[color=blue][b]Характеристики:[/b][/color]
1. [b]Объем:[/b] 6,3 м?
2. [b]Тип:[/b] Ёмкость В2-ОМВ
3. [b]Инвентарный номер:[/b] 10145
4. [b]Материал:[/b] Прочная конструкция из высококачественной стали.
5. [b]Предназначение:[/b] Для хранения и транспортировки различных жидкостей.
6. [b]Прочность:[/b] Долгий срок службы и устойчивость к воздействию внешних факторов.
7. [b]Безопасность:[/b] Соответствует стандартам безопасности.
[center][color=red][b]Где приобрести:[/b][/color] Посетите [https://vtormash.ru/katalog/7-kubov/jomkost-v2-omv-6-3m3-inv-10145][color=red]сайт Втормаш[/color][/url] для получения подробной информации о ёмкости В2-ОМВ 6,3м? инв.10145. Вы найдете там цены, технические характеристики и условия покупки.[/center]
카지노솔루션
30 Sep 2024Excellent post. , I am impressed! Very useful information, I really care about such information. I spent a long time searching for this specific information. Thanks and good luck.