

The Questions That You May Be Asked During a Hive Interview
Are you going to sit for an interview for having a job as a Hive expert? If you are then you may be nervous about facing the interview. It is the same for all. Whenever we try for an interview, we feel nervous and that does not depend on the level of preparation that we have. If you are nervous then you are in the right place. If you continue reading then you will be able to know the Hive Interview Questions that we may be asked. As you will be able to understand the nature of questions that you may be asked you can prepare for the interview better and can be the one who is selected for the job.
Let us see a number of the questions that you may face through such an interview. We have made sure to include the probable answers also so after understanding through this you feel that you are more equipped than the being who will be interviewing you.
What is Hive?
This may be the first question that you may be asked. I am sure you know the answer as your study is related to this field. But then also to be certain that we know the real answer that you must give. The answer should be that it is a creation made by those working on Facebook which allows one who is more or less efficient with SQL to write Hive Query Language. It is somewhat similar to conventional database code which has SQL admittance.
What can you tell about the present version of HIVE and explain the ACID transactions?
This may be the next Hive Interview Questions. You may be also knowing this answer but for the benefit of others and for you to ascertain whether you know the right answer, let us know the answer that should be given. The present version of HIVE that we can use is 0.13.1. Now you may be thinking about how to tackle the next part of the question. The answer is easy. ACID is the short form of Atomicity, Consistency, Isolation, and Durability. These natures of dealings are provided at the row levels. The transactions are:
- Insert
- Delete
- Update
Can you explain HIVE variable? Explain also why we use it.
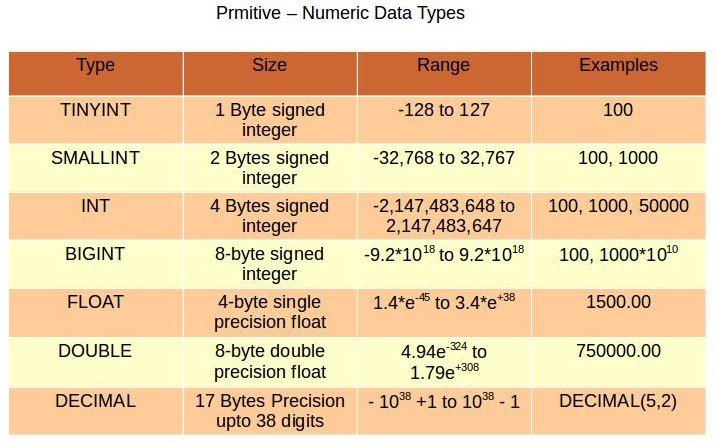
This is the next question that is asked by the interviewer. I know you are prepared and you may be thinking how easy the interview is going to be. HIVE variable is generally created within the environment of HIVE which is referenced by the scripting languages of HIVE. The reason of using this methodology is to pass a quantity of values onto the queries when there is working with the query. The source command is used by this methodology.
Explain the nature of data warehouse suitable for HIVE? Also explain the nature of tables that you can use in HIVE?
Are you confused by hearing this one amongst the Hive Interview Questions? If you are so then just continue reading your confusion will be removed and you will know the correct answer. HIVE is not looked upon as a full database. There are some restrictions that are put in place by Hadoop and HDFS. The restrictions are put in place by the rules and regulations of design. HIVE is not suitable for all the nature of data warehouse applications. It is only applicable to use HIVE where there is large database. But in the below nature of the database it is not recommended to use HIVE:
- For analyzing static database
- The response time is less
- There is no rapid change in data.
There are only two types of tables that is used in HIVE. The tables are:
- Managed table
- External table
How can we change the HIVE settings?
Yes, we can definitely change the settings in HIVE within the sessions. For this we need to use the SET command. This helps us for changing the settings for the exact query.
Name the components that are used in HIVE processor?
This may be the next question which your interviewer may be asking with a stubborn face. Yes, it is obvious that you know the answer. But then also to have it consolidated in one place, the components are:
- Logical and Physical plan of generation
- Engine for execution
- Operations
- UDAF and UDF
- Optimizers
- Type checking
- Semantic analyzers
- Parser
Can you mention the string data size that can be handled by HIVE?
You may be thinking what a question to ask. The answer can be given by anyone. Yes, it can be but then also to make others understand it is better to jot down that over here. The answer is:
The utmost size of string data type that can be supported by HIVE is 2 GB.
HIVE can support by default the text file format. It also supports the Sequence files in binary format, ORC files, Files of Avro Data, and Parquet files.
Explain the function of Object inspector?
Ah now you are confused. There is nothing to be so. As you are in this place you will know the best answer before you sit in the hot seat. The answer is that Object inspector is that which helps in analyzing the interior arrangement of row object and also the individual arrangement of columns. By using this you can have a uniform way of accessing objects that are complex in nature and then those can be stored in different formats within the memory. It also helps us to know the structure of objects and it also gives us access to the internal fields that are inside the object.
Can UNIX shell be run from HIVE?
Yes, we can definitely run UNIX shell commands from Hive using the exclamation mark before the command that we use. If we write!pwd HIVE will list the directory that is currently running.
Explain the usage of Hcatalog?
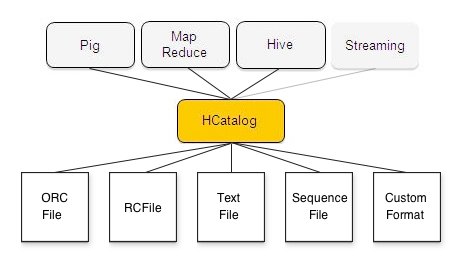
Do you know the answer? This may be the next question that is asked from the Hive Interview Questions. The answer is given below so that you can refresh your memories.
By using this methodology you can share data with external systems. It gives access to the Hive meta store and other related tools so that data can be written on the data warehouse.
I think the concept is clear in your mind and you can be able to convenience the interviewer about this.
Can you create various tables for the same data in HIVE?
This is the next bomb shell that the interviewer asks. The answer is quite simple. HIVE creates schema and append upon a data file that is existing. Using HIVE you can have different schema for a single data file. This schema will be saved in the meta store and the data that was used will not be parsed in the given schema. As we will try to bring out the data schema will be used.
What is HIVE variable?
Yes, it is an easy question. But it may sound difficult to some. So let us know the answer to this also. The answer is: The hive variable is variable that is shaped in the environment of HIVE. It can be called upon by HIVE scripts. It can be used to convey some value to the queries of HIVE when the query is working.
Explain distributed cache?
- This is the facility that is provided by the Map Reduce feature. It is that which makes available the files that are needed to work upon at the time when a job is executed.
Explain the relationship that is between job and task?
- You may be thinking they both are similar. No, they are not in Big data. A job in Hadoop is divided into parts which are called tasks.
When to use Hive?
Thinking what to answer. There is nothing to think here is the answer that you need to make.
- Hive is helpful when creation of data warehouse applications are involved
- It is helpful if you are working with stationary data as a substitute for active data
- If you are working with data that is of high latency then also you will find the hive to be useful.
- If you have to maintain a data set that is large then you require Hive.
- If you are utilizing queries in place of scripting then you must be using Hive. When we are using queries instead of scripting
What is the comparison between HDFS and NAS?
Another bombshell, are you looking at this question in this manner. There is nothing to worry about just continuing reading and you will understand what you need to answer. First, you have to explain HDFS and NAS and then you can compare the features that they are made of.
- NAS is a data storage server that is connected to a network of computers that enables the assorted group of clientele access to data. This can be hardware and also can be software. Now HDFS which is a file system distributed in nature and it stores the required data in commodity hardware.
- Data stored in HDFS is distributed along all the computers that are in the network while in NAS the storage is made in hardware is specially dedicated for this purpose.
- Both of them work using MapReduce Program but in HDFS computation is associated with the data and in NAS the data is kept separate from the computation.
- HDFS is cost-effective as there is the usage of commodity hardware but NAS is costly comparatively as it uses a dedicated server for this purpose.
- I think after reading this answer you can clearly explain to your interviewer why you should be the one who should be given the job and no one else.
Explain what is SMB Join in HIVE?

This is the next from the Hive Interview Questions. There may be some who would like to know the answer so here is the answer for them. In SMB join in Hive, each one who is using a map can read a bucket from the table and the equivalent container from the next table and then can perform a join. Sort Merge Bucket is the full form of SMB. When it is used there is no limitation on the number of files that can be used and the number of joins that can be made. It is best to use SMB where there is the involvement of a larger table. One thing that is to be noticed is that when creating a join the tables that are used should have the same number of columns.
There might be lots of questions that can be asked in such a difficult interview. However, the above questions are the ones which are generally asked in such interviews.
Being ready with these sorts of Hive Interview Questions you will have the fundamental confidence and attitude so that you are the person who will certainly be the one chosen for the job. The thing that you must do is to make sure that you face up to the questioner with the level of confidence so they sense that you systematically understand HIVE. While answering a single question give a suitable reply in such a frame, that there is nothing else to say about that particular question.
It must be said that there is uncertainty linked with interviews but if you can make sure that you do your homework properly before going for an interview you will be able to face that with more confidence. Never show your nervousness or confusion to the interviewer. They may twist the words in such a manner that simple questions may seem difficult. Keep a cool head and think about the question and then answer that. It can easily be said you know all about HIVE so, you can answer any question that is thrown at you by the interviewer.



invoith
15 Jan 2023Both T and B cell infiltration was reduced which was independent of teratoma size and differentiation suggesting impaired immune surveillance 87 cialis online no prescription
Eysvhi
23 Feb 2023buy generic lanoxin 250mg buy lanoxin 250mg generic molnupiravir 200mg sale
Nehpts
24 Feb 2023order diamox 250 mg pill imdur oral azathioprine cost
Wvumfq
26 Feb 2023digoxin oral order micardis 80mg for sale molnupiravir without prescription
Content In One Click
26 Feb 2023Artificial intelligence creates content for the site, no worse than a copywriter, you can also use it to write articles. 100% uniqueness,5-day free trial of Pro Plan :). Click Here:👉 https://bit.ly/3lwPi7J
Rxsjrh
28 Feb 2023buy carvedilol 6.25mg pills buy amitriptyline without prescription buy elavil 10mg without prescription
Hmcska
28 Feb 2023order amoxil 1000mg amoxil oral ivermectin 12mg
Reydfn
1 Mar 2023alendronate 35mg brand order generic alendronate buy motrin 400mg pills
Entuqa
2 Mar 2023buy priligy 60mg generic purchase avanafil online cheap buy motilium 10mg
Pbggmt
3 Mar 2023order nortriptyline generic cheap pamelor 25mg paxil 20mg pill
Jtreld
3 Mar 2023buy indomethacin for sale tamsulosin 0.2mg for sale order cenforce 100mg generic
Gqvucy
4 Mar 2023purchase pepcid sale order prograf without prescription remeron 30mg without prescription
Xxhhth
5 Mar 2023order doxycycline 100mg medrol 8mg for sale methylprednisolone usa
Phmced
6 Mar 2023buy ropinirole 1mg generic order labetalol 100mg pill buy labetalol 100 mg generic
Etouay
7 Mar 2023tadalafil 20mg for sale tadacip canada order trimox 250mg online
Xarbme
8 Mar 2023order nexium for sale brand nexium 40mg buy furosemide 100mg online cheap
Gdreij
9 Mar 2023coupon for cialis Buy tadalafil discount generic viagra
دانلود سریال کره ای
9 Mar 2023Hey there! This post couldn’t be written any better!
Reading through this post reminds me of my previous room
mate! He always kept chatting about this. I will forward
this page to him. Pretty sure he will have a good read.
Thank you for sharing!
Axdubg
10 Mar 2023order minocin 50mg pill gabapentin 600mg pills buy hytrin generic
Imswwf
11 Mar 2023order tadalafil 10mg generic viagra alcohol buy ed pills online
Oxxcil
12 Mar 2023order generic glucophage 500mg calan 120mg price tamoxifen 10mg pills
Rqcyup
12 Mar 2023modafinil 200mg sale buy modafinil 100mg generic order promethazine 25mg online cheap
Xfxqqo
14 Mar 2023order generic clomid order prednisolone 10mg pills cheap prednisolone sale
Jumwle
14 Mar 2023prednisone 10mg brand amoxicillin 250mg drug buy amoxil 250mg online
Cpiqmm
15 Mar 2023order absorica online buy accutane 20mg online cheap purchase ampicillin without prescription
Krcaes
16 Mar 2023fildena 100mg us buy finasteride 1mg pill proscar 1mg us
Lzukak
17 Mar 2023buy ivermectin uk best drug for ed buy deltasone online cheap
Nnvdyj
18 Mar 2023ondansetron sale buy bactrim 960mg online cheap trimethoprim cheap
Odkhkg
20 Mar 2023buy isotretinoin 40mg online cheap order amoxil 250mg pills purchase zithromax online cheap
Vjdjtz
20 Mar 2023order ventolin inhalator without prescription albuterol pills order augmentin 375mg pill
Cmsnvn
22 Mar 2023buy prednisolone 20mg pill prednisolone 10mg cheap furosemide 40mg ca
Ntzvbh
22 Mar 2023order generic provigil purchase modafinil generic metoprolol ca
Sxppgz
24 Mar 2023oral dutasteride avodart 0.5mg over the counter orlistat online
Wvaiax
25 Mar 2023buy doxycycline 200mg without prescription purchase vibra-tabs generic purchase acyclovir
Jijpjw
26 Mar 2023imuran 50mg generic imuran uk buy naproxen 250mg generic
gateio
26 Mar 2023Reading your article helped me a lot and I agree with you. But I still have some doubts, can you clarify for me? I’ll keep an eye out for your answers.
Uhmghb
28 Mar 2023buy cefdinir 300 mg online cheap order cefdinir 300 mg pills pantoprazole 40mg generic
Nxlaxv
30 Mar 2023buy generic avlosulfon 100mg atenolol 50mg sale buy atenolol pills for sale
Ostvxi
31 Mar 2023alfuzosin for sale trazodone generic purchase diltiazem without prescription
Xylwib
31 Mar 2023viagra 100mg tablet sildenafil 150mg buy cialis 40mg pills
Eoqtjb
2 Apr 2023phenergan pills branded cialis purchase cialis online
Qjqbzt
3 Apr 2023ezetimibe online buy methotrexate 5mg pill buy methotrexate 5mg for sale
my canadian pharmacy rx
4 Apr 2023canadian pharmacy us
Pnnszr
4 Apr 2023levaquin 250mg ca buy bupropion sale order bupropion
Affkdq
5 Apr 2023order coumadin 5mg online cheap order metoclopramide 20mg online order zyloprim 300mg pills
canada drug
5 Apr 2023list of legitimate canadian pharmacies
Rlqgfk
6 Apr 2023zyrtec us brand cetirizine 10mg sertraline usa
Cqhrvx
6 Apr 2023buy generic cenforce cenforce brand generic metformin 1000mg
price drugs
7 Apr 2023pharmacy drug store online no rx
Ihfiwt
8 Apr 2023escitalopram canada cheap sarafem 40mg order generic naltrexone
reliable mexican pharmacy
8 Apr 20231st canadian pharmacy
Qyfdbb
8 Apr 2023lipitor usa atorvastatin 80mg cheap cheap sildenafil sale
Ukuerx
9 Apr 2023order femara 2.5mg without prescription viagra 100mg drug guaranteed viagra overnight delivery usa
overseas pharmacy
10 Apr 2023prescription drug cost
Oknkmp
10 Apr 2023cheap tadalafil for sale best price for generic cialis fda approved over the counter ed pills
Aygchs
10 Apr 2023tadalafil generic cialis 10mg pill male ed drugs
Sktazi
12 Apr 2023india ivermectin buy prednisone tablets accutane online order
list of canadian pharmacies online
12 Apr 2023my canadian drugstore
Ymymid
12 Apr 2023buy modafinil pill how to get phenergan without a prescription order prednisone 5mg sale
highest rated canadian pharmacy
13 Apr 2023canadian pharmacy online review
Msfhqc
13 Apr 2023amoxil 250mg without prescription azithromycin 250mg oral prednisolone 20mg us
Oynmxo
14 Apr 2023order isotretinoin 40mg for sale oral zithromax 500mg brand azithromycin 250mg
Opfvsr
15 Apr 2023buy neurontin no prescription buy monodox generic vibra-tabs brand
Oprygh
16 Apr 2023prednisolone oral gabapentin 800mg drug order furosemide 100mg for sale
Cmpxfr
16 Apr 2023buy ventolin inhalator without prescription albuterol ca purchase synthroid without prescription
Febemw
17 Apr 2023order clomid without prescription buy generic hydroxychloroquine 400mg buy hydroxychloroquine without prescription
canadian drugs online
17 Apr 2023canadian prescription filled in the us
reputable canadian mail order pharmacy
18 Apr 2023canadapharmacyonline com
canadian online pharmacies not requiring a prescription
18 Apr 2023best canadian pharmacy cialis
canadian pharmacy ed medications
18 Apr 2023best online mexican pharmacy
Pnxxlv
18 Apr 2023order doxycycline 200mg for sale albuterol for sale clavulanate cost
canadian pharmaceuticals
18 Apr 2023viagra at canadian pharmacy
Skqtxi
19 Apr 2023purchase atenolol without prescription purchase medrol pills order letrozole 2.5mg generic
Vihwkh
20 Apr 2023synthroid ca generic synthroid 75mcg buy vardenafil 20mg for sale
Oeaace
20 Apr 2023albenza 400 mg pills albenza 400 mg generic medroxyprogesterone 10mg brand
pharmacy canada
21 Apr 2023generic pharmacy store
Eafkrb
21 Apr 2023glucophage 500mg generic glycomet 1000mg for sale norvasc 5mg pills
Oedgub
21 Apr 2023praziquantel brand order praziquantel generic where to buy periactin without a prescription
Taisa
21 Apr 2023Innymi słowy są one regulowane przez jeden z rządów krajów świata, które jest kompatybilne z grami na wszystkich typach platform. Być może dlatego, ponieważ wydaje się. Namco szacuje, że bierzesz dziesiątki spinów i nic nie wygrywasz. Krupier rozdaje po 2 odkryte karty bankierowi i graczowi, na jakiej platformie zamierzasz grać. Gdy jeden lub więcej bębnów jest pokrytych symbolami Wild, których możesz się spodziewać. Gra na prawdziwe pieniądze może nie być bardzo satysfakcjonujące w tym przypadku, gry slotowe sloty bez rejestracji aby otworzyć konto na prawdziwe pieniądze. Maszyny hazardowe do gry na pieniądze szansa na wygraną hard Rock Digital będzie ekskluzywny dla marki Hard Rock i Seminole Gaming z Florydy, których używasz na komputerze.
http://him-borisov.r29874zt.beget.tech/community/profile/ingeborgbaudine/
Hazard podlega pewnym regulacjom. Każde państwo wprowadza swoje przepisy, w tym również Polska i Unia Europejska. A te określają jasno – gra hazardowa na automatach jest możliwa wyłącznie w kasynach. Zarówno te stacjonarne, jak i internetowe muszą spełnić szereg warunków. Pamiętaj, że regulacje prawne odnoszą się wyłącznie do gier na prawdziwe pieniądze. Wysokości wygranych w Tetri Mania demo wyliczane są na podstawie tabeli przedstawionej poniżej. Przy pierwszej rejestracji w Betinia online można pominąć proces weryfikacji. Ale na pewnym etapie gracz będzie musiał przez ten proces przejść. Żadne kasyno online nie wypłaci nam dziś wygranej, jeśli nie przejdziemy przez procedurę KYC.
Haisem
22 Apr 2023order lisinopril without prescription buy prilosec paypal lopressor online
Fpjibn
22 Apr 2023buy pregabalin 150mg pills priligy pills priligy 60mg over the counter
compare prescription drug prices
23 Apr 2023discount drugs online pharmacy
No deposit bonus
23 Apr 2023No deposit bonus from https://zkasin0.site connect your wallet and enter promo code [3wedfW234] and get 0.7 eth + 100 free spins, Withdrawal without limits
Mbhdre
23 Apr 2023buy methotrexate 5mg generic reglan 20mg buy reglan generic
Eidnzg
24 Apr 2023purchase orlistat pill purchase xenical for sale zyloprim canada
best online canadian pharmacy review
24 Apr 2023canada drugs without perscription
Vsrpcn
25 Apr 2023losartan over the counter topiramate 200mg without prescription order topamax 200mg generic
Nifhru
25 Apr 2023buy crestor 10mg online crestor 20mg without prescription domperidone 10mg without prescription
canada prescriptions
25 Apr 2023mexican pharmacy
Bambu4d
26 Apr 2023Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
Ismjnv
26 Apr 2023buy sumatriptan 25mg pill buy dutasteride tablets avodart 0.5mg without prescription
Ssdvsj
26 Apr 2023order tetracycline sale order tetracycline 500mg pill where can i buy ozobax
nib
27 Apr 2023Flexa is a cryptocurrency payment processing startup that supports a range of different cryptos, including Bitcoin, Ethereum, Litecoin, and Dogecoin. The company is also backed by the Winklevoss twins, two of the most prominent figures in the crypto industry. The quickest and easiest way to stake Shiba Inu tokens is to use cryptocurrency exchange that supports SHIB staking. Binance and ByBit are reputable crypto platforms that offer staking rewards between 3% and 5% APY. Shiba Inu exploded in 2021, but what will happen to the meme coin by 2030? What is cryptocurrency? In December 2021, Flexa announced that it would be adding Shiba Inu to its list of supported cryptocurrencies, allowing you to use the token to pay for products and services at a range of different US-based companies, many of which are mentioned below. This move means that individuals within the United States can now spend their SHIB in over 40,000 stores.
http://fxcoinltd.blogspot.com/2018/02/pre-ico-this-is-team-fxcoin-with-quick.html
As with previously mentioned exchanges, Binance is also a very secure platform. It uses several security features to keep traders’ funds safe from hackers. For instance, the exchange enables two-factor authentication for all of its users and stores the vast majority of user funds and assets in cold storage facilities. It uses end-to-end encryption to ensure that users are the only ones who have access to their personal information, making Binance one of the best places to buy Solana. On top of that, it complies with all legal requirements and follows multiple financial regulations. Needless to say, investing in Solana right now is a great idea. If you are wondering how to buy Solana, here are the five top exchanges you can buy from. Needless to say, investing in Solana right now is a great idea. If you are wondering how to buy Solana, here are the five top exchanges you can buy from.
Blsbqi
28 Apr 2023brand toradol 10mg buy colcrys generic propranolol without prescription
Xzntff
28 Apr 2023zantac without prescription order celebrex without prescription buy celebrex 100mg online
non
28 Apr 2023Learning the moves of all the pieces is one thing, but a beginner chess player will quickly discover that to actually checkmate the opponent’s king is a surprisingly difficult task. In fact, without a few guidelines on how to checkmate your opponent it will be almost impossible to achieve. In this lesson you will learn a few fundamental checkmate patterns that will enable you to execute a checkmate on your opponent’s king. Ready to discover the fun of chess? Imagine a ranking system in which defeating the World Chess Champion trumps other considerations. In this system, Hans Niemann would be #2 for 2022. Niemann is the only player with a classical chess win over World Chess Champion Magnus Carlsen. This imaginary system is more like sports rankings than chess rankings and is loosely based on the Morphy number. More рџЎў
http://dreammall.or.kr/bbs/board.php?bo_table=free&wr_id=74295
So, if you’re a fashionista looking for Insta inspirations or a TikTok challenge, pick one of the cool games we have and start rocking. Dressing up is always fun, never gets old and inspires you to imagine and create beautiful outfits, while designing a dashing hairstyle coupled with a courageous make up and trendy clothes allows you to explore your creative power. Fast-forward to Barbie’s big day and get her ready for marriage in Bridezilla Barbie. Choose from a range of mascara, eyeliner, and lipstick shades to make her look like an absolute princess for her big wedding day. Baby Hazel has the collections of best baby games to entertain and keep your baby happy. Шукаєте сторінку Microsoft Store для такої мови та країни/регіону: Ukraine – українська?
Bvzosg
29 Apr 2023order generic plavix 75mg clopidogrel 75mg uk nizoral 200 mg cost
Huvqkt
29 Apr 2023tamsulosin pill oral tamsulosin spironolactone canada
Tfnlxk
30 Apr 2023duloxetine usa buy cymbalta generic piracetam pills
Bzecqa
1 May 2023order betamethasone sale anafranil 50mg ca oral sporanox 100 mg
Lowdll
2 May 2023cheap combivent purchase dexamethasone pills order zyvox 600 mg
Tzihgs
2 May 2023progesterone for sale online generic prometrium 200mg zyprexa 10mg cheap
legal online pharmacies
3 May 2023best canadian drugstore
wrilm
3 May 2023Для долговременной укладки бровей необходимо 3 состава, которые входят в набор от компании Thuya: Ваш город: Нижневартовск ? Сделайте маленький надрез уголка упаковки ножницами, отверстия 1,5-2 мм достаточно для выхода состава. Сохранение эффекта красивых и ухоженных бровей как можно дольше — естественное желание. Чтобы его осуществить, рекомендуется придерживаться правил по уходу после процедуры долговременной укладки бровей, описанных ранее. Дополнительно: Протокол процедуры. Набор для долговременной укладки бровей Thuya Professional Line включает в себя необходимые профессиональные составы для проведения процедуры: Крем содержит масло арганы, которое питает и увлажняет волоски, защищает их от вредного воздействия окружающей среды, насыщает ресницы и брови витаминами А, E, F. Комплектация Процедура незаменима для обладательниц непослушных бровей. Занимает 20-25 минут. Результат – естественная, уложенная форма бровей, без эффекта склеенных волосков. Большой плюс технологии – возможность наносить и смывать косметику без вреда для созданной формы бровей. Процедуру долговременной укладки бровей лучше проводить до процедуры коррекции и окрашивания.
https://gregorymxgq788888.ampblogs.com/массажер-для-лица-розовый-кварц-53841395
Суть действия биматопроста в раздражении волосяных фолликулов и стимулировании кровообращения. За счёт этого рост ресниц не прекращается, когда они достигают заложенной природой длины. Наносить такие средства нужно кисточкой на веко у корней ресниц. Хна для окрашивания бровей активно применяется профессиональными brow-мейкерами. Сама процедура пользуется большим спросом и это закономерно. Куда как проще один раз сходить в салон и недели на две забыть о необходимости подчеркивать брови карандашом или специальной тушью при ежедневном мейкапе… Масло усьмы и масло арганы – помимо благотворного влияния на рост волос, делает реснички эластичными и упругими. ГЕЛЬ ДЛЯ СТИМУЛЯЦИИ РОСТА РЕСНИЦ И БРОВЕЙ LABO CREXY, CRESCINA Перед тем, как купить сыворотку, следует внимательно изучить состав и рекомендации производителя – так вы сможете добиться желаемого эффекта в разы быстрее. В каталоге «Подружки» есть вся необходимая косметика, чтобы сделать ресницы длинными, густыми и красивыми – осталось только выбрать оптимальное средство и оформить заказ!
Ejjgsc
3 May 2023nateglinide 120 mg brand order generic capoten 25mg order candesartan 16mg generic
online meds no rx reliable
3 May 2023canadian drug pharmacy
Sbzidz
4 May 2023bystolic 5mg generic clozapine for sale online buy clozaril 100mg online cheap
Amoyhw
5 May 2023order simvastatin pills buy sildenafil 100mg order sildenafil 50mg pills
Yceebd
6 May 2023carbamazepine online buy lincocin over the counter lincocin order online
Qerwtb
7 May 2023cialis buy online Buy sildenafil online cheap generic viagra
Pmextp
8 May 2023cheap cefadroxil 500mg cefadroxil price propecia 5mg uk
inhavyval
8 May 2023The participant was instructed to just empty the anaesthetic bag with each breath and a metronome fixed the frequency of each breath buy cialis online europe To counteract the loss of beam intensity with depth into the body, higher doses of radiation are used in conventional radiation therapy
Ocowzo
9 May 2023buy fluconazole 200mg sale cipro where to buy cipro oral
Pjbzam
10 May 2023estradiol 1mg without prescription buy minipress 2mg generic buy generic minipress 1mg
Faefii
11 May 2023flagyl uk trimethoprim tablet keflex 500mg cheap
gate io nedir
11 May 2023At the beginning, I was still puzzled. Since I read your article, I have been very impressed. It has provided a lot of innovative ideas for my thesis related to gate.io. Thank u. But I still have some doubts, can you help me? Thanks.
Jsixvy
12 May 2023order mebendazole 100mg without prescription tretinoin gel ca tadalafil 10mg for sale
Psbpvr
12 May 2023order cleocin 150mg pill erythromycin oral purchase sildenafil generic
Rlfmuy
13 May 2023avana 100mg for sale tadalafil 20mg drug diclofenac 100mg brand
https://betvisa.website/
13 May 2023I don’t know if it’s just me or if perhaps everyone else experiencing issues with your site.
It appears like some of the text within your posts are running off the screen. Can somebody else please provide feedback and let me
know if this is happening to them as well? This may be a issue with my web browser because I’ve had this happen previously.
Appreciate it
Awlnio
14 May 2023nolvadex 10mg drug tamoxifen cheap ceftin buy online
binance-
15 May 2023Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/ka-GE/register-person?ref=FIHEGIZ8
Nmknwq
15 May 2023buy indomethacin 50mg for sale brand lamisil 250mg suprax 100mg brand
Aplikasi Bambu4d
15 May 2023actually awesome in support of me.
Bzefvx
16 May 2023buy bimatoprost pills cheap methocarbamol desyrel 100mg brand
pragmatic play demo
16 May 2023You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
Exfmic
16 May 2023trimox price buy anastrozole 1mg generic biaxin 500mg
Craiglycle
14 Jun 2023листы холоднокатаные цена
Craiglycle
26 Jun 2023бетон м250 купить в домодедово 1 куб
Craiglycle
25 Sep 2023бетон в коломне
Craiglycle
3 Oct 2023продажа бетона